-
실전 예제 - 마케팅 데이터 분석 03 (Revenue)빅데이터/Data-Analysis 2022. 2. 24. 11:52
패스트캠퍼스 '직장인을 위한 파이썬 데이터분석 올인원 패키치 Online' 참조
- AARRR의 'Revenue' 파트를 공부 해 볼 예정. 어떻게 'Revenue(수익)'을 극대화 할 수 있는지를 알아 보자
- 이번에는 쇼핑몰 데이터로 고객 데이터 분석을 통해 고객 세그먼트를 도출하고 그 사용법을 고려해볼 예정
▶ 마케팅에서 흔히 듣는 용어 고객 세그먼트와 페르소나. 이 둘을 간단히 이해 해 보자
- 세그먼트(Segment)
정량화 할 수 있는 같은 속성을 공유하는 그룹을 나누는 의미. 대부분의 마케팅 담당자는 하나의 방식으로 고객을 세분화하는것이 아닌 비지니스 목적에 따라 여러가지 방식으로 세분화하는 방식을 주로 사용. 예로 라이프스타일, 취향, 성별 등등. 세그먼트에도 여러 종류가 있다. 내부, 외부, 전술적, 전략적 세그먼트로 나뉜다.
(자세한 사항은 다음 링크 참조
https://thetales.co/2017/05/14/%ec%9d%b4%ec%95%bc%ea%b8%b0-21-%ec%84%b8%ea%b7%b8%eb%a8%bc%ed%8a%b8segment%ec%99%80-%ed%8e%98%eb%a5%b4%ec%86%8c%eb%82%98persona/) - 페르소나(Persona)
세그먼트로 분류를 나눴다면 여기에 조금 더 디테일을 주는 방법. 타겟 고객의 대리 이미지를 만들어 회사가 원하는 특정의 목표를 달성하는데 있어 유사한 행동 패턴을 가진 구릅들을 페르소나들로 식별하여 관리함
(자세한 사항은 같은 링크를 참조 하자!)
01 문제정의
- 데이터는 아래 링크에서 다운
https://www.kaggle.com/vjchoudhary7/customer-segmentation-tutorial-in-python* 기본 세팅
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns df = pd.read_csv('Mall_Customers.csv') df.head()
- CustomerID - 고객들에게 배정된 유니크한 고객 번호 입니다.
- Gender - 고객의 성별 입니다.
- Age - 고객의 나이 입니다.
- Annual Income (k$) - 고객의 연소득 입니다.
- Spending Score (1-100) - 고객의 구매행위와 구매 특성을 바탕으로 mall에서 할당한 고객의 지불 점수 입니다.
▶ 문제정의
- 주어진 데이터가 정확하다고 가정
- 주어진 변수들을 가지고 고객세그먼트를 도출 그리고 거기서 가장 적절한 수의 고객 세그먼트를 도출
- 도출시에 각 세그먼트별 특성을 도출하고 그 특성에 맞는 활용방안 및 전략을 고민해볼 예정
02 EDA
# 데이터 확인 df.shape (200, 5) # 결측치 확인 print(df.info()) print() print(df.isnull().sum()) # Column Non-Null Count Dtype --- ------ -------------- ----- 0 CustomerID 200 non-null int64 1 Gender 200 non-null object 2 Age 200 non-null int64 3 Annual Income (k$) 200 non-null int64 4 Spending Score (1-100) 200 non-null int64 dtypes: int64(4), object(1) memory usage: 7.9+ KB None CustomerID 0 Gender 0 Age 0 Annual Income (k$) 0 Spending Score (1-100) 0 dtype: int64# 기술통계 확인 df.describe()
- 주로 mean을 확인 하여야 한다. 평균 나이는 38.85세, 평균 년 소득은 60k, 평균 년 지출은 50.2로 나옴
# 변수간 corr 확인 df.corr() # 히트맵으로 확인 corr = df.corr() sns.heatmap(corr, annot=True)
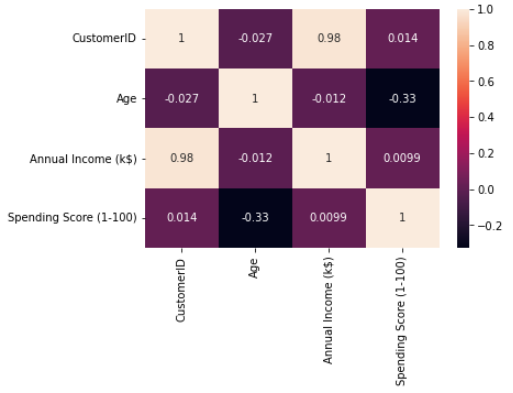
- 상관관계들이 그렇게 눈에 띄는것들이 없다
# pairplot으로 다시 확인 sns.pairplot(df[['CustomerID', 'Gender', 'Age', 'Annual Income (k$)', 'Spending Score (1-100)']]);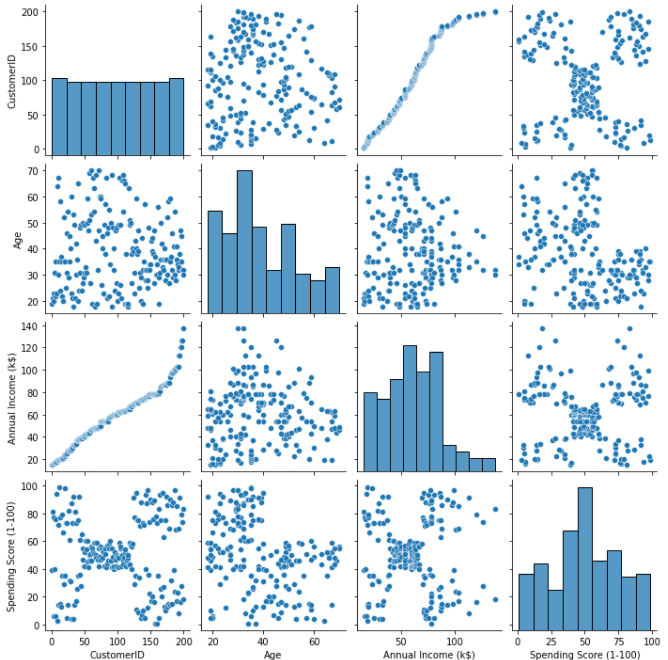
- 샘플데이터여서 그런지 몇개가 의도적으로 만들어진것이 보인다. 특히 년소득과 년지출 사이에 이미 특정한 세그먼트들이 분포되어있는것처럼 보인다
- 고객 아이디는 그닥 의미가 없다고 봤으나 다시 돌아가서 히트맵과 패어플롯을 보면 고객아이디와 년 소득과의 상관관계 및 선형에 가까운 관계를 그린다는것을 볼 수 있다
- 성별에 따른 년소득 분포도와 년소득에 따른 소비 분포도를 확인 해 보자
# 성별 분포도 확인 - countplot을 이용 sns.countplot(data=df, x='Gender');
# 성별에 따른 년소득 sns.lmplot(data=df, x='Age', y='Annual Income (k$)', hue='Gender', fit_reg=False);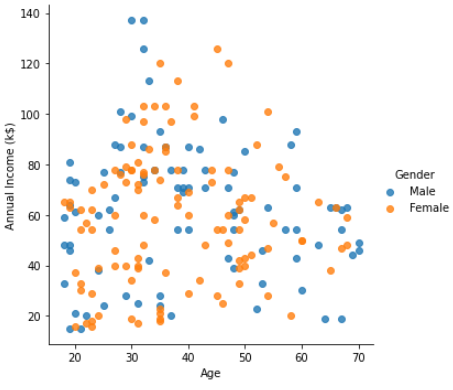
- 성별로는 그렇게 차이가 없는 듯 하다
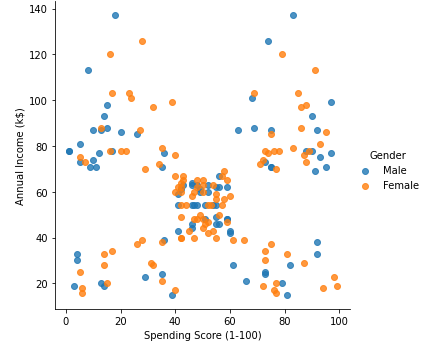
# 년소득에 따른 소비 분포도 sns.lmplot(data=df, x='Spending Score (1-100)', y='Annual Income (k$)', hue='Gender', fit_reg=False);
- 이것또한 성별로는 차이가 없는 듯 하다
- 성별에 따른 분포도를 pairplot/boxplot으로 확인
# pairplot으로 다시 확인 sns.pairplot(df[['CustomerID', 'Gender', 'Age', 'Annual Income (k$)', 'Spending Score (1-100)']], hue='Gender'); #박스 플롯으로 확인 sns.boxplot(x='Gender', y='Age', hue='Gender', palette=['m','g'], data=df)
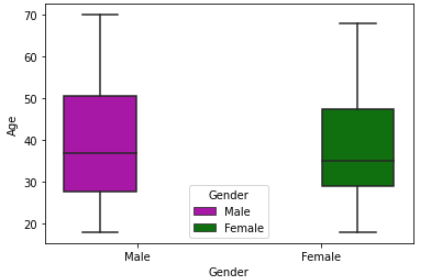
- 성별이 아주 그렇게 크게 영향을 미치는것으로는 보이지 않는다. 하지만 년소득과 소비점수에 따라 세그먼트를 잡을 수 있을 것으로 보인다
03 고객 세그먼트 클러스터링
- 'K-means' 를 통해 가장 빠르고 단순하게 클러스터링을 할 예정
- sklearn의 cluster 서브 패키지의 KMeans를 이용
- 'KMeans'의 중요 하이파라미터들:
n_clusters: 군집의 갯수 (default=8)
init: 초기화 방법. "random"이면 무작위, "k-means++"이면 K-평균++ 방법.(default=k-means++)
n_init: centroid seed 시도 횟수. 무작위 중심위치 목록 중 가장 좋은 값을 선택한다.(default=10)
max_iter: 최대 반복 횟수.(default=300)
random_state: 시드값.(default=None)
from sklearn.cluster import KMeans # X1에 'Age', 'Spending Score (1-100)'의 값을 넣어 줌 x1 = df[['Age', 'Spending Score (1-100)']].values # 군집화를 위한 빈 리스트 생성 inertia = [] # 군집수 n을 1~11까지 돌아가며 x1에 대해 k-means 알고리즘을 적용하여 inertia를 리스트에 저장 for n in range(1, 11): algorithm = (KMeans(n_clusters=n)) algorithm.fit(x1) inertia.append(algorithm.inertia_) inertia [171535.5, 75949.15601023019, 45840.67661610867, 28165.58356662934, 23819.442236543742, 19498.412640311184, 15523.684014328752, 13006.48362885102, 11520.34610781251, 10160.705687830688]- 'inertia' - 군집 내의 데이터들이 얼마나 퍼져 있는지(얼마나 뭉쳐있는지) 또는 응집도 등은 inertia의 값으로 확인 한다. inertia는 각 데이터로부터 자신이 속한 군집의 중심까지의 거리를 의미하기 때문에 inertia값이 낮을수록 군집화가 더 잘됬다고 볼 수 있다
- 즉 1~11번 돌렸을때 마지막 어디서 급격히 꺾임이 줄어드는지를 볼 필요가 있다
# inertia를 그래프로 확인 plt.figure(1, figsize=(16,5)) plt.plot(np.arange(1,11), inertia, 'o') plt.plot(np.arange(1,11), inertia, '-', alpha=0.8) plt.xlabel('Number of Clusters'), plt.ylabel('Inertia');
클러스터 4개정도부터 급격히 줄어드는것을 볼 수 있다. - 군집 4개로 시각화
# 군집수 4개로 시각화 algorithm = (KMeans(n_clusters=4, init='k-means++', n_init=10, max_iter=300, tol=0.0001, random_state=111, algorithm='elkan')) algorithm.fit(x1) labels1 = algorithm.labels_ centroids1 = algorithm.cluster_centers_ # 시각화를 위한 배열/차원 세팅 h = 0.02 x_min, x_max = x1[:,0].min() -1, x1[:,0].max() +1 # 17, 70 y_min, y_max = x1[:,1].min() -1, x1[:,1].max() +1 # 1, 99 # .meshgrid() - 2/3차원 그리드 # .arange() - 배열로 반환 (최소, 최대, 간격) # xx,yy = 2차원 등고선 함수를 그릴때 사용 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # .c_ = 여러행렬을 column으로 이어 붙이기 위해 사용 # 이어붙일 행렬들은 xx.ravel(), yy.ravel() # .ravel() - 다차원 배열을 1차원 배열로 바꿔줌 # 즉 z는 xx,yy의 2차원 값을 1차원으로 바꿔서 예측 z = algorithm.predict(np.c_[xx.ravel(), yy.ravel()]) plt.figure(1, figsize=(15, 7)) plt.clf() # 위에서 만든 플롯을 지움 # .reshape 차원과 모양을 변경하여 행렬을 반환 z = z.reshape(xx.shape) plt.imshow(z, interpolation='nearest', extent=(xx.min(), xx.max(), yy.min(), yy.max()), cmap = plt.cm.Pastel2, aspect='auto', origin='lower') plt.scatter(x='Age', y='Spending Score (1-100)', data=df, c=labels1, s=200) plt.scatter(x=centroids1[:, 0], y=centroids1[:,1], s=300, c='red', alpha=0.5) plt.ylabel('Spending Score (1-100)'), plt.xlabel('Age');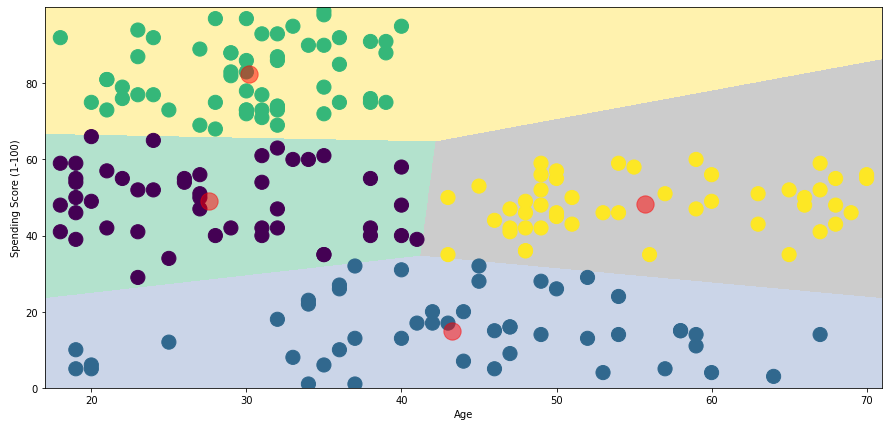
- 연령과 소비점수를 기반으로 클러스터링이 완료 되었다
- 빨간점은 중심 클러스터링이다
- 노란색 바탕에 초록색 점들은 나이는 어리지만 소비점수는 높다 - 저연령 고소비군
- 초록색바탕에 보라색 점들은 저연령에 중소비군
- 회색바탕에 노란색 점들은 고연령에 중소비군
- 파란색 바탕에 파란색 점들은 전연령대에 저소비군
- 이를 바탕으로 전략을 세워보자면
이 쇼핑몰의 경우 소비점수가 높은 고객들은 40세 이하의 젊은 고객들
소비 점수가 높은 고객들은 연령대가 비슷한 만큼 비슷한 구매패턴과 취향을 가질 가능성이 높음
해당 군집의 소비자 특성을 더 분석해본 뒤 해당 군집의 소비자 대상 VIP 전략을 수립
소비점수가 중간정도인 고객들에게는 연령에 따라 두개 집단으로 접근
소비점수가 낮은 고객군은 연령대별로 종소비점수 군집에 편입되로록 접근 - 사실 군집 분석은 여러 변수들을 사용해서 차원축소를 주로 한다. 하지만 두가지만 써서 하면 2차원으로 쉽게 시각화를 진행한 후 분석이 가능하다
- 지금까지 나이와 소비점수로 고객 세그먼트를 구분 지었다. 다음으로는 년소득과 소비점수로 클러스터링을 해보자
# 년소득과 소비점수 클러스터링 # X2에 'Annual Income (k$)', 'Spending Score (1-100)'의 값을 넣어 줌 x2 = df[['Annual Income (k$)', 'Spending Score (1-100)']].values # 군집화를 위한 빈 리스트 생성 inertia = [] # 군집수 n을 1~11까지 돌아가며 x1에 대해 k-means 알고리즘을 적용하여 inertia를 리스트에 저장 for n in range(1, 11): algorithm = (KMeans(n_clusters=n)) algorithm.fit(x2) inertia.append(algorithm.inertia_) # inertia를 그래프로 확인 plt.figure(1, figsize=(16,5)) plt.plot(np.arange(1,11), inertia, 'o') plt.plot(np.arange(1,11), inertia, '-', alpha=0.8) plt.xlabel('Number of Clusters'), plt.ylabel('Inertia');
급격히 줄어드는 부분은 5로 보인다 # 군집수 5개로 시각화 algorithm = (KMeans(n_clusters=5, init='k-means++', n_init=10, max_iter=300, tol=0.0001, random_state=111, algorithm='elkan')) algorithm.fit(x2) labels2 = algorithm.labels_ centroids2 = algorithm.cluster_centers_ # 시각화를 위한 배열/차원 세팅 h = 0.02 x_min, x_max = x2[:,0].min() -1, x2[:,0].max() +1 # 17, 70 y_min, y_max = x2[:,1].min() -1, x2[:,1].max() +1 # 1, 99 # .meshgrid() - 2/3차원 그리드 # .arange() - 배열로 반환 (최소, 최대, 간격) # xx,yy = 2차원 등고선 함수를 그릴때 사용 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # .c_ = 여러행렬을 column으로 이어 붙이기 위해 사용 # 이어붙일 행렬들은 xx.ravel(), yy.ravel() # .ravel() - 다차원 배열을 1차원 배열로 바꿔줌 # 즉 z는 xx,yy의 2차원 값을 1차원으로 바꿔서 예측 z2 = algorithm.predict(np.c_[xx.ravel(), yy.ravel()]) plt.figure(1, figsize=(15, 7)) plt.clf() # 위에서 만든 플롯을 지움 # .reshape 차원과 모양을 변경하여 행렬을 반환 z2 = z2.reshape(xx.shape) plt.imshow(z2, interpolation='nearest', extent=(xx.min(), xx.max(), yy.min(), yy.max()), cmap = plt.cm.Pastel2, aspect='auto', origin='lower') plt.scatter(x='Annual Income (k$)', y='Spending Score (1-100)', data=df, c=labels2, s=200) plt.scatter(x=centroids2[:, 0], y=centroids2[:,1], s=300, c='red', alpha=0.5) plt.ylabel('Spending Score (1-100)'), plt.xlabel('Age');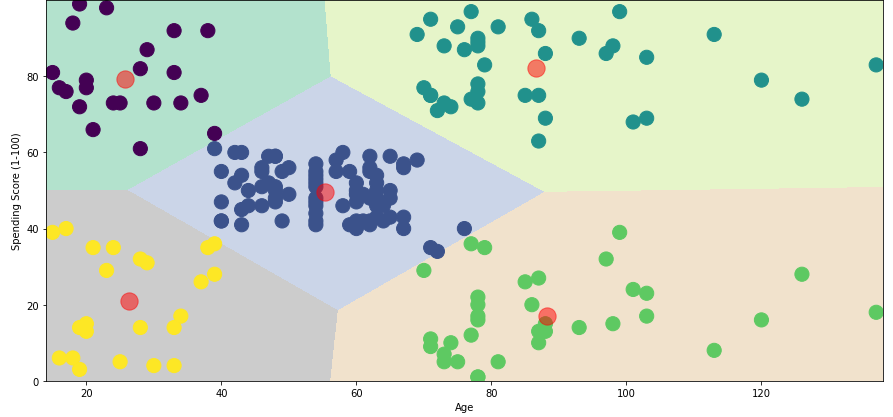
- 처음에 시각화로 봤던 분포와 거의 동일하다고 볼 수 있다.
- 실제 데이터는 절대로 이렇게 나올 수 없으니 참고 해야하며, 년소득/소비점수 에 따른 군집별로 전략을 세울 수 있다
- 예로 가장 위의 두 고객세그먼트를 보면 왼쪽 군집은 소비는 높은데 연소득은 낮고, 오른쪽은 소득도 높고 소비도 높게 보인다. 둘다 소비를 많이 하니 VIP로 보고 왼쪽에는 가격에 민감한 전략, 오른쪽은 더 소비를 할 수있는 여러 프로모션을 제공한다던지 등의 전략이 가능 하겠다
'빅데이터 > Data-Analysis' 카테고리의 다른 글
실전 예제 - 마케팅 데이터 분석 06 (Referral) (0) 2022.02.25 실전 예제 - 마케팅 데이터 분석 05 (Revenue - 03) (0) 2022.02.24 실전 예제 - 마케팅 데이터 분석 04 (Revenue - 02) (0) 2022.02.24 실전 예제 - 마케팅 데이터 분석 02 (Activation/Retention) (0) 2022.02.23 실전 예제 - 마케팅 데이터 분석 01 (Acquisition) (0) 2022.02.21