-
Selenium 기초 및 활용 하기 5 - 네이버 뉴스 댓글 스크래핑빅데이터/Selenium 2022. 1. 12. 16:29
유투버 '이수안컴퓨터연구소' 강의 참조
- news.naver.com 에 들어가서 뉴스들을 보면 아래와 같이 댓글을 달 수 있다. 이들을 스크래핑 해볼 예정

* 기본 세팅
import selenium from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.by import By import time import pandas as pd from selenium.common.exceptions import ElementClickInterceptedException, NoSuchElementException, ElementNotInteractableException #(클릭시 없을때, 엘리멘트 자체가 없을떄, 엘리멘트가 상호작용을 못할때 ) #웹브라우저를 띄우지 않고 진행하기 위한 설정 chrome_options = webdriver.ChromeOptions() chrome_options.add_argument('--headless') chrome_options.add_argument('--no-sandbox') chrome_options.add_argument('--disable-dev-shm-usage')01 URL 세팅
- 가장 많이 본 뉴스를 골라서 들어가면 적절한 양의 댓글들이 있다. 이 주소를 복사해서 URL로 쓰자

def scraping(): wd = webdriver.Chrome('chromedriver', options=chrome_options) wd.implicitly_wait(3) #대기 시간 news_url = 'https://news.naver.com/main/ranking/read.naver?mode=LSD&mid=shm&sid1=001&oid=469&aid=0000652202&rankingType=RANKING' wd.get(news_url)02 다른 뉴스 URL을 넣으면 처리가 되도록 함수 처리
def scraping(): .... news_scraping(news_url, wd) def news_scraping(news_url, wd):03 필요 정보 들고 오기
- 프레스 가져 오기

def news_scraping(news_url, wd): press = wd.find.element(By.XPATH, '//*[@id="main_content"]/div[1]/div[1]/a/img').get_attribute('title')- 타이틀 가져 오기
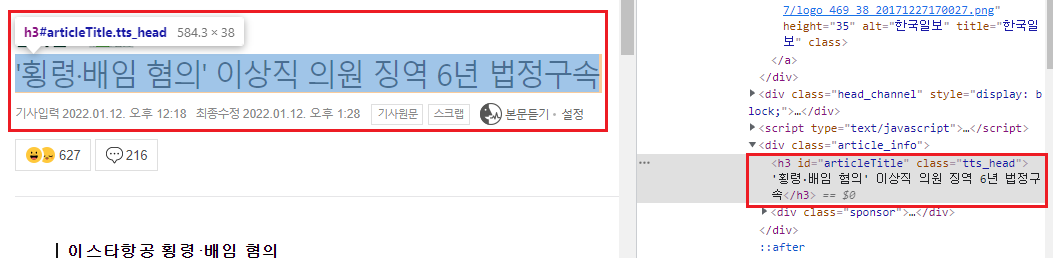
title = wd.find.element(By.ID, 'articleTitle').text- 날짜 가져 오기

datetime = wd.find.element(By.CLASS_NAME, 't11').text- 본문 들고 오기

article = wd.find.element(By.ID, 'articleBodyContents').text▶ 이 <div> 태그는 들고 오는 내용 수정이 추가적으로 필요 하다.
article = wd.find.element(By.ID, 'articleBodyContents').text article = article.replace("// flash 오류를 우회하기 위한 함수 추가", "") article = article.replace("function _flash_removeCallback() {}", "") article = article.replace("\n", "") article = article.replace("\t", "")- 사람들 반응 들고 오기

<ul> 태그안에 <li> 태그로 각 감정 + 개수가 담겨 있고, 기사 추천 수 또한 <div>로 나뉘어져있는것을 볼 수 있다. good = wd.find_element(By.XPATH, '//*[@id="spiLayer"]/div[1]/ul/li[1]/a/span[2]').text warm = wd.find_element(By.XPATH, '//*[@id="spiLayer"]/div[1]/ul/li[2]/a/span[2]').text sad = wd.find_element(By.XPATH, '//*[@id="spiLayer"]/div[1]/ul/li[3]/a/span[2]').text angry = wd.find_element(By.XPATH, '//*[@id="spiLayer"]/div[1]/ul/li[4]/a/span[2]').text want = wd.find_element(By.XPATH, '//*[@id="spiLayer"]/div[1]/ul/li[5]/a/span[2]').text recommend = wd.find_element(By.XPATH, '//*[@id="toMainContainer"]/a/em[2]').text print("뉴스: ", [title, press, datetime, article, good, warm, sad, angry, want, recommend, news_url])* 뉴스 스크래핑 최종 코드
더보기def news_scraping(news_url, wd):
press = wd.find_element(By.XPATH, '//*[@id="main_content"]/div[1]/div[1]/a/img').get_attribute('title').text
title = wd.find_element(By.ID, 'articleTitle').text
datetime = wd.find_element(By.CLASS_NAME, 't11').text
article = wd.find_element(By.ID, 'articleBodyContents').text
article = article.replace("// flash 오류를 우회하기 위한 함수 추가", "")
article = article.replace("function _flash_removeCallback() {}", "")
article = article.replace("\n", "")
article = article.replace("\t", "")
good = wd.find_element(By.XPATH, '//*[@id="spiLayer"]/div[1]/ul/li[1]/a/span[2]').text
warm = wd.find_element(By.XPATH, '//*[@id="spiLayer"]/div[1]/ul/li[2]/a/span[2]').text
sad = wd.find_element(By.XPATH, '//*[@id="spiLayer"]/div[1]/ul/li[3]/a/span[2]').text
angry = wd.find_element(By.XPATH, '//*[@id="spiLayer"]/div[1]/ul/li[4]/a/span[2]').text
want = wd.find_element(By.XPATH, '//*[@id="spiLayer"]/div[1]/ul/li[5]/a/span[2]').text
recommend = wd.find_element(By.XPATH, '//*[@id="toMainContainer"]/a/em[2]').text
print("뉴스: ", [title, press, datetime, article, good, warm, sad, angry, want, recommend, news_url])
return [title, press, datetime, article, good, warm, sad, angry, want, recommend, news_url]
04 1차 테스트
def scraping(): wd = webdriver.Chrome('chromedriver', options=chrome_options) wd.implicitly_wait(3) #대기 시간 news_idx = 0 news_df = pd.DataFrame(columns=("Title","Press","DateTime","Article","Good","Warm","Sad","Angry","Want","Recommend","URL")) news_url = 'https://news.naver.com/main/ranking/read.naver?mode=LSD&mid=shm&sid1=001&oid=469&aid=0000652202&rankingType=RANKING' wd.get(news_url) news_df.loc[news_idx] = news_scraping(news_url, wd) news_idx += 1 wd.close() return news_df news_df = scraping() news_df
▶ 뉴스는 적절히 잘 스크래핑이 되었고 이제 이 뉴스에 대한 댓글을 긁어와 보자.
05 뉴스 댓글 스크래핑
- scraping() 함수에 댓글 함수를 추가하여 진행

- 댓글 검사

한 댓글이 <ul> 태그안에 <li> 태그로 구성이 되어 있다. 
댓글을 다 보여주는 형태는 아니고 댓글 더보기를 통해 모든 댓글을 볼 수 있고 
또 들어가 보면 더보기로 계속해서 모든 댓글이 다 보일때까지 펼칠 수 있는 형태이다. 
댓글에 답글도 달 수 있는 형태이다. 답글을 눌러서 댓글을 다 가져오도록 세팅 해야 한다. 또한 클릭을 하면 답글이 나오지만 아무것도 페이지에는 변화가 없다. 그래서 .click()으로는 안될 수 도 있다. - 1차 테스트
def comments_scraping(news_url, wd): try: btn_view = wd.find_element(By.CLASS_NAME, 'u_cbox_btn_view_comment').click() #댓글 더 보기 print("[댓글 더 보기]", end="") time.sleep(1) while True: #댓글 더보기 이후 더 보기를 계속 클릭해서 끝까지 가야하므로 while문을 써준다. wd.find_element(By.CLASS_NAME,'u_cbox_page_more').click() #더 보기 print("[더 보기]", end="") time.sleep(1) except: pass btn_reply_list = wd.find_elements(By.CLASS_NAME, 'u_cbox_btn_reply') #답글 버튼 들고 옴 for btn_reply in btn_reply_list: btn_reply.send_keys('\n') #.click()으로 변화가 없는 부분은 이렇게 처리 한다. print("[답글]", end="") time.sleep(1)
굿! - 댓글 스크래핑
1) 유저네임

2) 날짜

3) 댓글

4) 좋아요/싫어요

- 2차 테스트전에 발견한 이슈. 댓글이 삭제되거나 부적잘한 형태도 있다. 처리 해줘야 한다.

좋아요/싫어요가 없으니 이를 가지고 구분 지어서 처리하면 될듯 하다. def comments_scraping(news_url, wd): try: btn_view = wd.find_element(By.CLASS_NAME, 'u_cbox_btn_view_comment').click() #댓글 더 보기 print("[댓글 더 보기]", end="") time.sleep(1) while True: #댓글 더보기 이후 더 보기를 계속 클릭해서 끝까지 가야하므로 while문을 써준다. wd.find_element(By.CLASS_NAME,'u_cbox_page_more').click() #더 보기 print("[더 보기]", end="") time.sleep(1) except: pass btn_reply_list = wd.find_elements(By.CLASS_NAME, 'u_cbox_btn_reply') #답글 버튼 들고 옴 for btn_reply in btn_reply_list: btn_reply.send_keys('\n') #.click()으로 변화가 없는 부분은 이렇게 처리 한다. print("[답글]", end="") time.sleep(1) print("[댓글 스크래핑]") comments_idx = 0 comments_df = pd.DataFrame(columns=("Contents","Name","Datetime","Like","Dislike","URL")) comments = wd.find_elements(By.CLASS_NAME, 'u_cbox_comment_box') #댓글 박스 들고 옴 for comment in comments: try: name = comment.find_element(By.CLASS_NAME, 'u_cbox_nick').text date = comment.find_element(By.CLASS_NAME, 'u_cbox_date').text contents = comment.find_element(By.CLASS_NAME, 'u_cbox_contents').text recomm = comment.find_element(By.CLASS_NAME, 'u_cbox_cnt_recomm').text unrecomm = comment.find_element(By.CLASS_NAME, 'u_cbox_cnt_unrecomm').text print(f" 댓글 #{comments_idx+1}:", [contents, name, date, recomm, unrecomm, news_url]) comments_df.loc[comments_idx] = [contents, name, date, recomm, unrecomm, news_url] comments_idx += 1 except NoSuchElementException: # print("[삭제되거나 부적절한 댓글]") continue return comments_df- 2차 테스트
더보기def scraping():
wd = webdriver.Chrome('chromedriver', options=chrome_options)
wd.implicitly_wait(3) #대기 시간
news_idx = 0
news_df = pd.DataFrame(columns=("Title","Press","DateTime","Article","Good","Warm","Sad","Angry","Want","Recommend","URL"))
news_url = 'https://news.naver.com/main/ranking/read.naver?mode=LSD&mid=shm&sid1=001&oid=018&aid=0005124750&rankingType=RANKING'
wd.get(news_url)
news_df.loc[news_idx] = news_scraping(news_url, wd)
news_idx += 1
comments_df = comments_scraping(news_url, wd)
wd.close()
return news_df, comments_dfnews_df, comments_df = scraping()
news_df
comments_df

굿!! '빅데이터 > Selenium' 카테고리의 다른 글
Selenium 기초 및 활용 하기 6 - 국회의원 스크래핑 (0) 2022.01.13 Selenium 기초 및 활용 하기 5-2 - 네이버 뉴스 댓글 스크래핑 (0) 2022.01.12 Selenium 기초 및 활용 하기 04-2 - 구글 이미지 스크래핑 (0) 2022.01.12 Selenium 기초 및 활용 하기 04 - 구글 이미지 스크래핑 (0) 2022.01.11 Selenium 기초 및 활용 하기 03 - CGV 영화 리뷰 스크래핑 (0) 2022.01.11