-
Selenium 기초 및 활용 하기 04 - 구글 이미지 스크래핑빅데이터/Selenium 2022. 1. 11. 20:31
유투버 '이수안컴퓨터연구소' 강의 참조
- 구글에서 이미지를 크롤링 할 예정. 보통 이러한 페이지에서 이미지를 바로 다운로드하면 원본이 아닌 작은 사이즈로 받아 진다.

- 원본 이미지를 받으려면 원하는 이미지를 클릭 한 후 열리는 창에서 다시 우클릭으로 받아야 받아진다.

- 또한 구글 이미지 같은 경우는 페이지로 나뉘는게아니라 스크롤을 계속 내리면서 업데이트 되는 형식이다. 스크롤을 일정 이상 내리면 더보기라는 버튼이 뜨는데 이 또한 클릭을 해줘야 계속해서 진행이 가능 하다

계속 내리다보면 결과가 없다고 나온다. * 기본 세팅
import selenium from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.by import By import time import pandas as pd #셀레니엄 예외처리용 from selenium.common.exceptions import ElementClickInterceptedException, NoSuchElementException, ElementNotInteractableException #(클릭시 없을때, 엘리멘트 자체가 없을떄, 엘리멘트가 상호작용을 못할때 ) import os #이미지 파일 다운로드 제어 용 import socket #소켓 에러 방지용 from urllib.request import urlretrieve #이미지 다운로드 라이브러리 from urllib.error import HTTPError, URLError #각종 에러 방지 라이브러리 (HTTP/URL 에러 방지) from PIL import Image # 이미지를 사용가능하도록 처리 하는 라이브러리 #웹브라우저를 띄우지 않고 진행하기 위한 설정 chrome_options = webdriver.ChromeOptions() chrome_options.add_argument('--headless') chrome_options.add_argument('--no-sandbox') chrome_options.add_argument('--disable-dev-shm-usage')- PIL가 되지 않으면 따로 설치를 해줘야 한다.
pip install Pillow01 스크래핑 시작전 세팅
- 소켓통신을 통하여 이미지 스크래핑을 진행 할 예정인데 너무 오래 걸릴시에는 정지하도록 세팅
socket.setdefaulttimeout(30)- 이미지 스크래핑 전/후로 저장 공간이 필요하므로 위치를 잡아 줘야 한다.
socket.setdefaulttimeout(30)#소켓 통신 시간 제어 wd = webdriver.Chrome('chromedriver', options=chrome_options) scraped_count = 0 #이미지 스크래핑 개수 카운트 용 path = './' #현재 사용하는 위치에서 검색어 폴더를 만들고 이미지 다운로드 용 query = input('검색어 입력: ') dir_name = path + query os.makedirs(dir_name) # 'dir_name' 으로 폴더 생성 print(f"[{dir_name} 디렉토리 생성]") scraping(dir_name, query) #실행 될 함수02 페이지 훑어 보기

도구를 눌러 이미지 사이즈는 큰것만 나오도록 하고 그 url을 쓴다 ▶ URL 주소를 수정하여 파라미터로 넘어오는값으로 검색이 되도록 한다.
https://www.google.com/search?q=sea&tbm=isch&hl=en&tbs=isz:l&rlz=1C1CHZN_koKR971KR971&sa=X&ved=0CAIQpwVqFwoTCIC5mMe9qfUCFQAAAAAdAAAAABAC&biw=942&bih=941 - 위의 주소를 보면 'sea'가 주소에 들어가고 이 'sea'가 검색이 되는것을 볼 수 있다. 이를 파라미터로 받자 url = f'https://www.google.com/search?q={query}&tbm=isch&hl=en&tbs=isz:l&rlz=1C1CHZN_koKR971KR971&sa=X&ved=0CAIQpwVqFwoTCIC5mMe9qfUCFQAAAAAdAAAAABAC&biw=942&bih=941'▶ 구글 이미지 페이지 특성상 전체 화면이 아니면 스크롤이 늘어나는 형태이다. 즉 항상 전체화면에서 스크래핑이 되도록 세팅
wd.get(url) wd.maximize_window() #전체화면으로 스크래핑▶ 스크롤 제어
def scraping(dir_name, query): global scraped_count url = f'https://www.google.com/search?q={query}&tbm=isch&hl=en&tbs=isz:l&rlz=1C1CHZN_koKR971KR971&sa=X&ved=0CAIQpwVqFwoTCIC5mMe9qfUCFQAAAAAdAAAAABAC&biw=942&bih=941' wd.get(url) wd.maximize_window() #전체화면으로 스크래핑 scroll_down()def scroll_down(): scroll_count = 0 pritn('[스크롤 다운 함수 시작!]') #스크롤을 내릴려면 위치값이 필요하다. 'execute_script()' 를 통해 스크롤 위치값(Height)을 가져 올 수 있음 last_height = wd.execute_script("return document.body.scrollHeight") after_click = False #스크롤을 계속내리다가 '더 보기'가 나오는지 체크용 while True: print(f"[스크롤 다운 중: {scroll_count}]") # 'scrollTo()' 함수를 써서 0부터 최대 위치값까지 스크롤을 함 wd.execute_script("window.scrollTo(0, document.body.scrollHeight);") scroll_count += 1 #스크롤이 최대로 갈때마다 카운트 time.sleep(1) #JS 액션이 실행되고 반응이 될때까지 기다릴 시간 new_height = wd.execute_script("return document.body.scrollHeight") # 최대값에 도달하면 스크롤이 다시 생성되니 거기서 다시 최대값 구함 if last_height == new_height: #스크롤이 더이상 되지 않다면 if after_click is True: #'더 보기'가 나온다면.. break else: try: more_button = wd.find_element(By.XPATH, '//*[@id="islmp"]/div/div/div/div[1]/div[2]/div[2]/input') if more_button.is_displayed(): # '더 보기' 버튼이 나오면 more_button.click() time.sleep(1) after_click = True except NoSuchElementException as e: print(e) break last_height = new_height03 1차 시도

모든 이미지가 <div> 태그에 담겨 있다. XPATH로 가져 온 후 각각의 이미지를 담아 보자 
각각의 이미지 태그 부분 서치 후 'Copy Selector' def scraping(dir_name, query): global scraped_count url = f'https://www.google.com/search?q={query}&tbm=isch&hl=en&tbs=isz:l&rlz=1C1CHZN_koKR971KR971&sa=X&ved=0CAIQpwVqFwoTCIC5mMe9qfUCFQAAAAAdAAAAABAC&biw=942&bih=941' wd.get(url) wd.maximize_window() #전체화면으로 스크래핑 scroll_down() div = wd.find_element(By.XPATH, '//*[@id="islrg"]/div[1]') img_list = div.find_elements(By.CSS_SELECTOR, '.rg_i Q4LuWd') for index, img in enumerate(img_list): try: #이 함수로 저장 이름, 인덱스, 이미지, 이미지 총 개수를 파라미터로 넘긴다 click_and_save(dir_name, index, img, len(img_list)) except▶ 위에서 언급했듯이 1차로 클릭하고 그 다음 저장이 이루어 진다. 이에 대한 함수가 필요
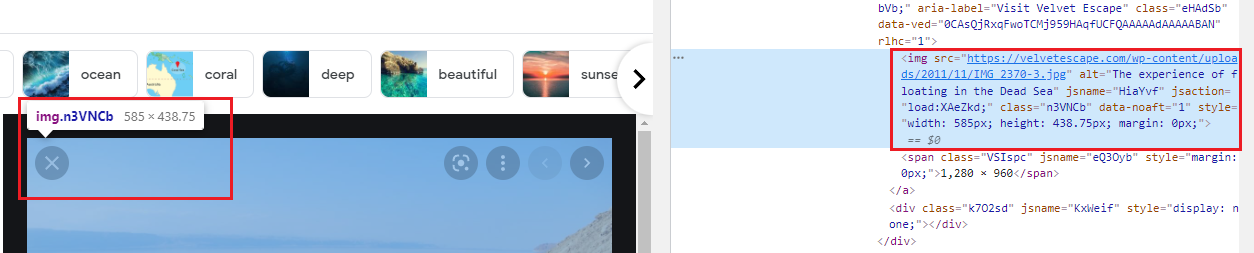
열린 이미지 창에서 다시 검사를 해서 이 원본 이미지 src를 들고 와야 한다. Xpath로 접근 하자 def click_and_save(dir_name, index, img, img_list_length): global scraped_count try: img.click() #이미지를 클릭 wd.implicitly_wait(3) #클릭 후 로드 시간이 필요하므로 대기 src = wd.find_element(By.XPATH, '//*[@id="Sva75c"]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div[2]/div/a/img').get_attribute('src') if src.split('.')[-1] == 'png': urlretrieve(src, dir_name + '/' + str(scraped_count + 1) + '.png') print(f' {index+1} / {img_list_length} PNG 이미지 저장 완료!') else: urlretrieve(src, dir_name + '/' + str(scraped_count + 1) + '.jpg') print(f' {index+1} / {img_list_length} JPG 이미지 저장 완료!') scraped_count += 1 except HTTPError as e: print(e) pass #PNG, JPG 이외는 다 제외- 이제 리스트 포문을 타면서 'click_and_save()' 함수를 타면 문제가 없지만 이미지 스크래핑은 수많은 예외가 존재 한다. 이를 처리 하자.
def scraping(dir_name, query): global scraped_count url = f'https://www.google.com/search?q={query}&tbm=isch&hl=en&tbs=isz:l&rlz=1C1CHZN_koKR971KR971&sa=X&ved=0CAIQpwVqFwoTCIC5mMe9qfUCFQAAAAAdAAAAABAC&biw=942&bih=941' wd.get(url) wd.maximize_window() #전체화면으로 스크래핑 scroll_down() div = wd.find_element(By.XPATH, '//*[@id="islrg"]/div[1]') img_list = div.find_elements(By.CSS_SELECTOR, '.rg_i Q4LuWd') for index, img in enumerate(img_list): try: #이 함수로 저장 이름, 인덱스, 이미지, 이미지 총 개수를 파라미터로 넘긴다 click_and_save(dir_name, index, img, len(img_list)) except ElementClickInterceptedException as e: # 클릭시 문제 발생하면 아래로 print(e) wd.execute_script("window.scrllTo(0, window.scrollY + 100)") #스크롤을 다시 하도록 time.sleep(1) click_and_save(dir_name, index, img, len(img_list)) except NoSuchElementException as e: print(e) wd.execute_script("window.scrllTo(0, window.scrollY + 100)") #스크롤을 다시 하도록 time.sleep(1) click_and_save(dir_name, index, img, len(img_list)) except ConnectionResetError as e: #연결 문제는 pass print(e) pass except URLError as e: #URL 문제시 PASS print(e) pass except socket.timeout as e: #소켓 통신 에러 pass print(e) pass except soket.gaierror as e: #소켓 통신 address 에러시 pass print(e) pass except ElementNotInteractableException as e: #엘리멘트 호환이 되지 않을때 print(e) break try: print("[스크래핑 종료 (성공률: %.2f%%)]" % (scraped_count / len(img_list) * 100.0)) except ZeroDivisionError as e: #성공률 계산시 0이 나오면 패스 print(e) pass wd.quit()'빅데이터 > Selenium' 카테고리의 다른 글
Selenium 기초 및 활용 하기 5 - 네이버 뉴스 댓글 스크래핑 (0) 2022.01.12 Selenium 기초 및 활용 하기 04-2 - 구글 이미지 스크래핑 (0) 2022.01.12 Selenium 기초 및 활용 하기 03 - CGV 영화 리뷰 스크래핑 (0) 2022.01.11 Selenium 기초 및 활용 하기 02 - 네이버웹툰 스크래핑 (0) 2022.01.10 Selenium 기초 및 활용 하기 01 - 설치 및 기본 기능 (0) 2022.01.07