-
BueatifulSoup 기초 및 활용 하기 02 - 순위 스크래핑빅데이터/BeautifulSoup 2021. 12. 14. 11:32
유투브 '이수안컴퓨터연구소' 참조
전 세계 웹사이트 순위 스크래핑
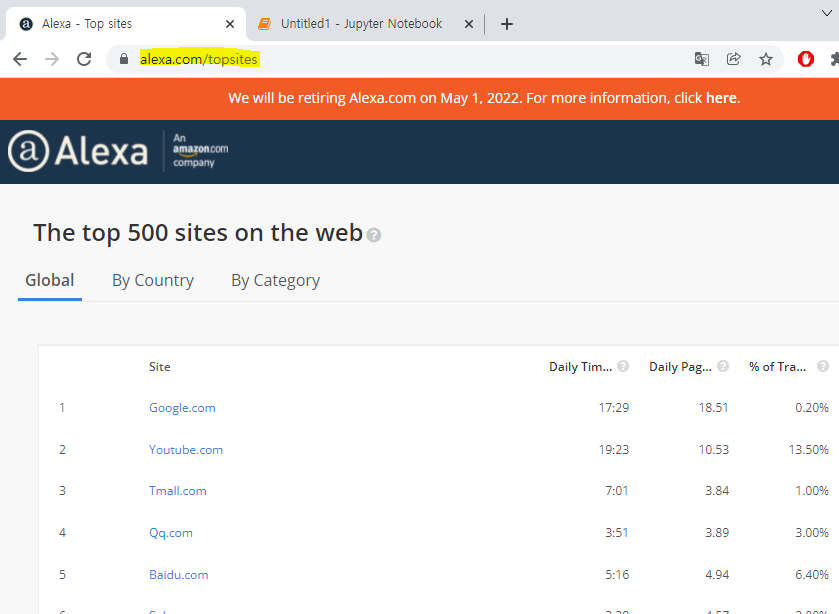
이 홈페이지가 현재 없어질 예정이라 찾기가 힘들다. 구글에서 직접 'The top 500 sites on the web' 이라고 치면 나온다 01 기본 타이틀 세팅
* 기본 세팅
from bs4 import BeautifulSoup as bs import requests import pandas as pd r = requests.get("https://www.alexa.com/topsites") r.status_code 2001) DF를 사용해서 데이터 만들기
soup = bs(r.content, 'html.parser') rank_df = pd.DataFrame(columns = ("Rank", "Site", "Daily Time on Site", "Daily Pageviews per Visitor", "% of Traffic From Search", "Total Sites Linking In"))강의에서는 위에서처럼 타이틀을 직접 타이핑한다. 하지만 매번 타이핑을 할 수 없을 뿐더러 타이틀이 수십개 넘어가는 경우 혹은 앞으로 한계가 분명할 것이다.
직접 타이틀도 긁어 와 보자

분석을 해보면 특정 <div> 클래스에서 <p> → <span> 태그에 타이틀이 담겨 있는것을 볼 수 있다 01 'Site' 긁기

CSS 셀렉터로 쉽게 긁자 title = [] title.append('Number') title.append(soup.select("#alx-content > div.row-fluid.TopSites.AlexaTool.padding20 > section.page-product-content.summary.padding20 > span > span > div > div > div > div.thead > div > div:nth-child(2)")[0].get_text()) print(title) ['Number', 'Site']*반드시 짚고 넘어가야할 문제
- 리스트로 받으면 쉽다는것을 몰랐다
- 'Site'와 다른 타이틀들의 구성이 다르다
- 번호 부분의 타이틀도 만들어 줘야 한다
- 'Site'는 잘 들고 왔으나 다른 타이틀은 리스트 형식으로 오는데 여기서 막혔다
- 리스트 형식으로 만들고 .append() 를 하면 쉽다는것을 몰랐다.
02 다른 타이틀 긁기
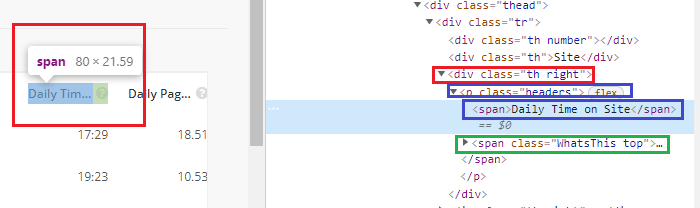
* 2가지 문제가 있다
- 다른 타이틀은 이런식으로 같은 패턴으로 반복이 된다
- 하지만 <span>밑에 또 다른 <span>으로 다른 문자열이 있다.

for i in range(3,7): title.append(soup.select(f"#alx-content > div.row-fluid.TopSites.AlexaTool.padding20 > section > span > span > div > div > div > div.thead > div > div:nth-child({i}) > p > span:nth-child(1)")[0].get_text()) title ['Number', 'Site', 'Daily Time on Site', 'Daily Pageviews per Visitor', '% of Traffic From Search', 'Total Sites Linking In']*반드시 짚고 넘어가야할 문제
- soup.select(f"생략> div.thead > div > div:nth-child({i}) > p > span:nth-child(1)")
여기서 뽑고자 하는 타이틀이 어디에서 분리되는지 찾는것이 중요하다 - 분리 되는 부분에서 포문을 돌려 그 타이틀 문자열만 들고온다
- 그리고 다시 .append()를 하면 해결
※ 결론은 리스트형식으로 자유 자재로 다룰 줄 알아야 하고, 뽑고자하는 문자열이 어디에 정확히 있고 그것을 어떻게 포문을 돌려 뽑을 것인가가 중요 하다!
03 DF 만들기
rank_df = pd.DataFrame(columns=title) rank_df
굿! - 타이틀을 컬럼에 넣고싶으면 반드시 '컬럼=내용' 을 선언 해줘야 한다
02 필요 데이터 뽑기
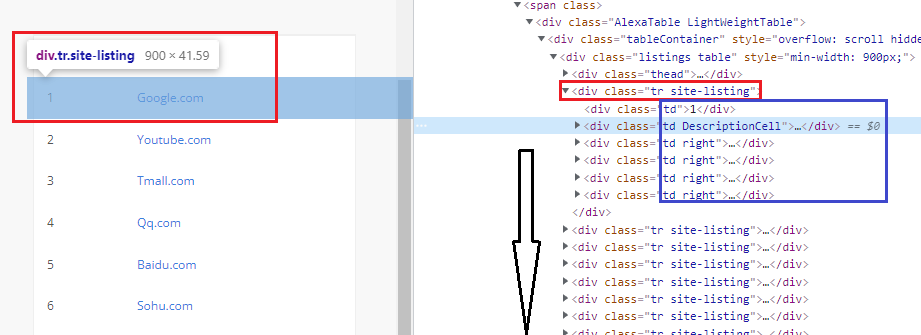
큰 &amp;amp;lt;div&amp;amp;gt; 태그안에 똑같은 패턴으로 반복이 되는것을 볼 수 있다 1) 랭크
sites = soup.find_all('div', {"class":"tr site-listing"}) for site in sites: rank = site.find('div', {"class":"td"}).get_text() print(rank) 1 2 3 ....- 'td' 는 하나이므로 find로 찾자
2) 사이트

사이트의 경우 &amp;amp;lt;div&amp;amp;gt; &amp;amp;rarr; &amp;amp;lt;p&amp;amp;gt; &amp;amp;rarr; &amp;amp;lt;a&amp;amp;gt; 태그안에 있다 - 이렇게 여러개로 걸쳐있으면서 <p> 와 <a> 태그에 다른 CSS라던지 특징이 없기때문에 이럴때는 CSS선택자를 쓰는게 좋다
#alx-content > div.row-fluid.TopSites.AlexaTool.padding20 > section.page-product-content.summary.padding20 > span > span > div > div > div > div:nth-child(2) > div.td.DescriptionCell > p > a- 마지막에 p > a 로 끝나는 것을 볼 수 있다.
sites = soup.find_all('div', {"class":"tr site-listing"}) for site in sites: rank = site.find('div', {"class":"td"}).get_text() website = site.select('p > a')[0].get_text() print(website) Google.com Youtube.com Tmall.com ...- 'sites' 변수로 ''div', {"class":"tr site-listing"}' 해당하는 모든 내용을 들고 옴
- 거기서 CSS선택자 전용 'select'를 써서 p > a 로 끝나는것을 들고 오되 리스트 반환이니 인덱스를 써서 텍스트를 들고옴
3) 나머지 정보

나머지 정보는 똑같은 &amp;amp;lt;div&amp;amp;gt; 태그에 &amp;amp;lt;p&amp;amp;gt; 태그로 스트링이 감싸져있는것을 알 수 있다 sites = soup.find_all('div', {"class":"tr site-listing"}) for site in sites: rank = site.find('div', {"class":"td"}).get_text() website = site.select('p > a')[0].get_text() infos = site.find_all('div', {"class":"td right"}) times = infos[0].get_text() pages = infos[1].get_text() traffics = infos[2].get_text() links = infos[3].get_text()- 먼저 find_all로 모든 정보를 들고 온다
- 'td_ right'에 의하여 4가지 정보를 다 가지고 있다
- 리스트 형식으로 4가지 정보가 들어 있기 때문에 거기서 다시 인덱싱 한다
- 인덱싱을 통해 맞는 정보를 각각 넣어 준다
03 DF에 데이터 넣기
sites = soup.find_all('div', {"class":"tr site-listing"}) for site in sites: rank = site.find('div', {"class":"td"}).get_text() website = site.select('p > a')[0].get_text() infos = site.find_all('div', {"class":"td right"}) times = infos[0].get_text() pages = infos[1].get_text() traffics = infos[2].get_text() links = infos[3].get_text() rank_df.loc[rank] = [rank, website, times, pages, traffics, links] rank_df- 'rank' 데이터를 기준으로 컬럼에 데이터를 넣게 함
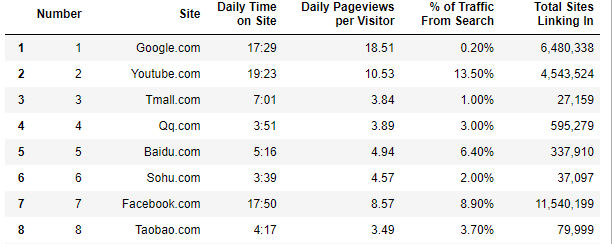 더보기from bs4 import BeautifulSoup as bsimport requestsimport pandas as pdr.status_codesoup = bs(r.content, 'html.parser')title = []title.append("Rank")title.append(soup.select("#alx-content > div.row-fluid.TopSites.AlexaTool.padding20 > section.page-product-content.summary.padding20 > span > span > div > div > div > div.thead > div > div:nth-child(2)")[0].get_text())print(title)for i in range(3,7):title.append(soup.select(f"#alx-content > div.row-fluid.TopSites.AlexaTool.padding20 > section > span > span > div > div > div > div.thead > div > div:nth-child({i}) > p > span:nth-child(1)")[0].get_text())titlerank_df = pd.DataFrame(columns=title)rank_dfsites = soup.find_all('div', {"class":"tr site-listing"})for site in sites:rank = site.find('div', {"class":"td"}).get_text()website = site.select('p > a')[0].get_text()infos = site.find_all('div', {"class":"td right"})times = infos[0].get_text()pages = infos[1].get_text()traffics = infos[2].get_text()links = infos[3].get_text()rank_df.loc[rank] = [rank, website, times, pages, traffics, links]rank_df
더보기from bs4 import BeautifulSoup as bsimport requestsimport pandas as pdr.status_codesoup = bs(r.content, 'html.parser')title = []title.append("Rank")title.append(soup.select("#alx-content > div.row-fluid.TopSites.AlexaTool.padding20 > section.page-product-content.summary.padding20 > span > span > div > div > div > div.thead > div > div:nth-child(2)")[0].get_text())print(title)for i in range(3,7):title.append(soup.select(f"#alx-content > div.row-fluid.TopSites.AlexaTool.padding20 > section > span > span > div > div > div > div.thead > div > div:nth-child({i}) > p > span:nth-child(1)")[0].get_text())titlerank_df = pd.DataFrame(columns=title)rank_dfsites = soup.find_all('div', {"class":"tr site-listing"})for site in sites:rank = site.find('div', {"class":"td"}).get_text()website = site.select('p > a')[0].get_text()infos = site.find_all('div', {"class":"td right"})times = infos[0].get_text()pages = infos[1].get_text()traffics = infos[2].get_text()links = infos[3].get_text()rank_df.loc[rank] = [rank, website, times, pages, traffics, links]rank_df'빅데이터 > BeautifulSoup' 카테고리의 다른 글
BueatifulSoup 기초 및 활용 하기 03 - 네이버 영화 스크래핑 (0) 2021.12.15 BueatifulSoup 기초 및 활용 하기 02 - 뮤직 순위 스크래링 (0) 2021.12.14 BueatifulSoup 기초 및 활용 하기 01 - 기초 문법 (0) 2021.12.13 웹 크롤링 - BeautifulSoup+Pandas를 이용한 데이터 분석 3 (0) 2021.12.13 웹 크롤링 - BeautifulSoup+Pandas를 이용한 데이터 분석 2 (0) 2021.12.11