-
웹 크롤링 - BeautifulSoup+Pandas를 이용한 데이터 분석 2빅데이터/BeautifulSoup 2021. 12. 11. 14:52
인프런 '코딩교양스쿨' 강의 참조
01 데이터 프레임으로 저장
*현재 까지 BeautifulSoup으로 아래 까지 진행
import requests from bs4 import BeautifulSoup as bs import pandas as pd import time headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'} url = "https://www.transfermarkt.com/spieler-statistik/wertvollstespieler/marktwertetop" r = requests.get(url, headers=headers) r.status_code soup = bs(r.content, 'html.parser') number = [] name = [] position = [] age = [] nation = [] team = [] value = [] for info in player_info: player = info.find_all("td") # print(player[0]) # print(player[3].get_text()) # print(player[7]) # print(player[8]) number.append(player[0].get_text()) name.append(player[3].get_text()) position.append(player[4].get_text()) age.append(player[5].get_text()) nation.append(player[6].img['alt']) team.append(player[7].a['title']) # value.append(player[8].b.get_text()) value.append(player[8].span['title'])- 판다스의 데이터 프레임을 이용하여 표 세팅
판다스를 이용해서 표 형태로 집어 넣을 시에는 딕셔너리 형태로 넣으면 된다!df = pd.DataFrame( { "Number":number, "Name":name, "Position":position, "Age":age, "Nation":nation, "Team":team, "Value":value } ) df
* 스크래핑시 데이터는 반드시 텍스트로 받아야 표에 텍스트 형태로 들어간다
데이터가 잘 만들어 진다! - 이 데이터를 csv 파일로 저장 해보기
df.to_csv('Most_Valueable_Players.csv', index=False)
- 여러 페이지 크롤링 하기
다음 페이지 구성도 완전히 첫페이지와 같다. 이럴때에는 주소로 접근해야 한다.
다음 페이지 주소가 나오는 웹페이지도 있지만 없다면 아래와 같이 접근 하자!
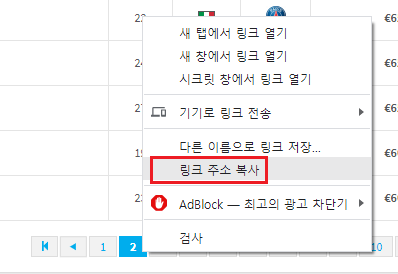
2 페이지 버튼에 마우스 우클릭 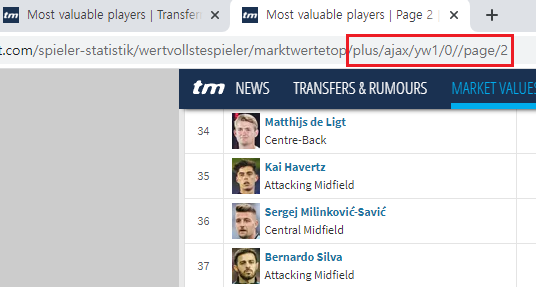
주소의 맨 뒷부분의 숫자가 바뀌면 페이지가 넘어가는 형태이다 1) 스크래핑 하기
* 세팅은 같지만 url 주소에 변화가 있다
import requests from bs4 import BeautifulSoup as bs import pandas as pd import time headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'} url = f"https://www.transfermarkt.com/spieler-statistik/wertvollstespieler/marktwertetop/plus/ajax/yw1/0//page/{}" r = requests.get(url, headers=headers) r.status_code soup = bs(r.content, 'html.parser')- url = f"https://www.transfermarkt.com/spieler-statistik/wertvollstespieler/marktwertetop/plus/ajax/yw1/0//page/{}"
- 주소 맨 뒷부분에 숫자형태로 페이지가 바뀌기 때문에 뒷 부분을 파라미터로 받도록 하고 포문을 돌리면 된다
import requests from bs4 import BeautifulSoup as bs import pandas as pd import time headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'} number = [] name = [] position = [] age = [] nation = [] team = [] value = [] for i in range(1, 3): url = f"https://www.transfermarkt.com/spieler-statistik/wertvollstespieler/marktwertetop/plus/ajax/yw1/0//page/{i}" r = requests.get(url, headers=headers) r.status_code soup = bs(r.content, 'html.parser') player_info = soup.find_all('tr', class_=['odd', 'even']) for info in player_info: player = info.find_all("td") # print(player[0]) # print(player[3].get_text()) # print(player[7]) # print(player[8]) number.append(player[0].get_text()) name.append(player[3].get_text()) position.append(player[4].get_text()) age.append(player[5].get_text()) nation.append(player[6].img['alt']) team.append(player[7].a['title']) # value.append(player[8].b.get_text()) value.append(player[8].text.strip()) time.sleep(1)2) 데이터 프레임 세팅
df = pd.DataFrame( { "Number":number, "Name":name, "Position":position, "Age":age, "Nation":nation, "Team":team, "Value":value } ) df
3) csv 파일로 저장
- 번외 연습
똑같은 웹페이지에서 다른 탭 정보 들고 와보기
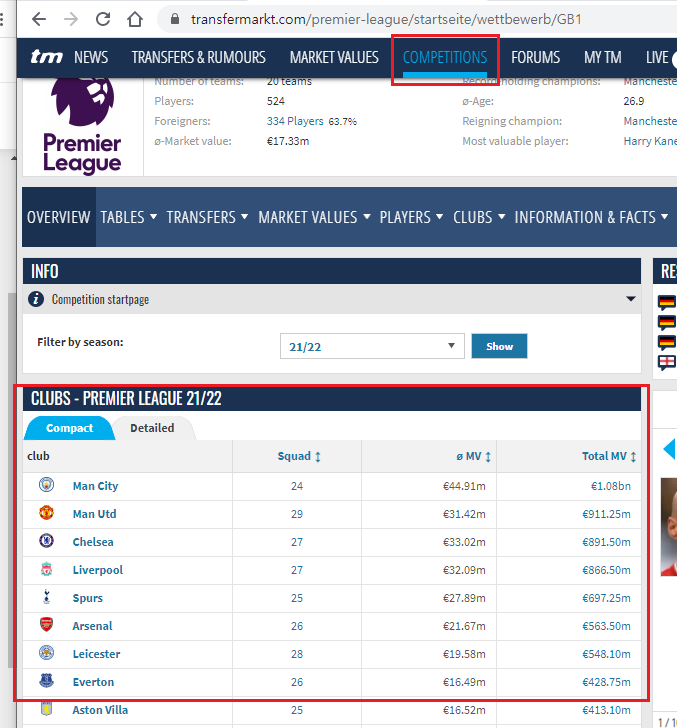
컴페티션 → 프리미어 탭을 선택하면 나오는 화면 1) 첫번째 난관
- 위에 배웠던대로 똑같은 패턴을 찾고 뽑으려 했으나 이 페이지에는 똑같은 형태의 테이블이 또 하나 있다

정말 테이블 형태, 태그 이름, 클래스 이름이 동일하다
soup.find_all('tr', class_=['odd', 'even'])→ 여기서 이렇게 찾으면 위에 팀 테이블과 아래 선수 테이블의 내용이 같이 불러와지는 오류가 있다.
2) 웹 구성을 다시 살펴서 다른 점을 찾아야 한다.
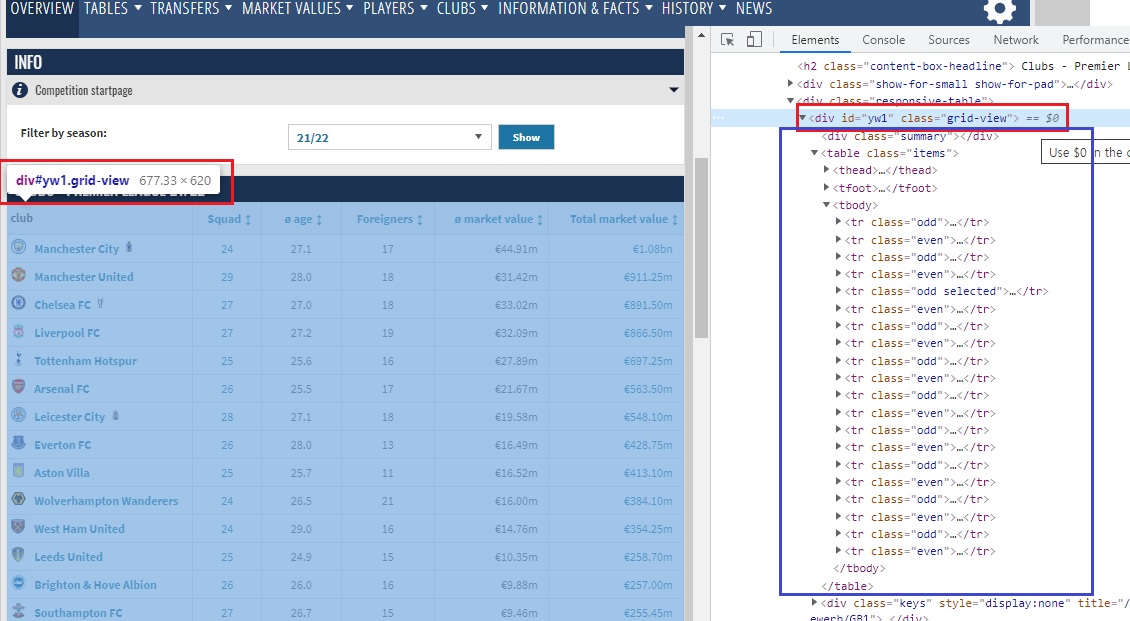
이런 웹페이지는 나같은 초보자에게는 정말 멘붕이다. 가장 큰 <div> 를 제외하고 아래 자식들이 가지고 있는 테이블 형식, 태그 이름 등이 모두 같다 다른점은 딱 하나 가장 큰 <div> 태그의 id가 다르다. 이것을 이용 하자!
3) id를 써서 찾기
import requests from bs4 import BeautifulSoup as bs import pandas as pd import time headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'} url = "https://www.transfermarkt.com/premier-league/startseite/wettbewerb/GB1" r = requests.get(url, headers=headers) r.status_code soup = bs(r.content, 'html.parser') data1 = soup.find('div', id='yw1') data2 = data1.find_all('tr', class_=['odd', 'even']) clubs = [] squad = [] mv = [] totalMv = [] for data in data2: info = data.find_all("td") clubs.append(info[1].get_text()) squad.append(info[3].get_text()) mv.append(info[6].get_text()) totalMv.append(info[7].get_text()) df = pd.DataFrame( { "Clubs":clubs, "Squad":squad, "MV":mv, "Total Mv":totalMv } ) df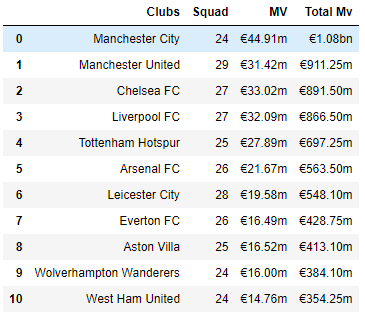
굿! '빅데이터 > BeautifulSoup' 카테고리의 다른 글
BueatifulSoup 기초 및 활용 하기 01 - 기초 문법 (0) 2021.12.13 웹 크롤링 - BeautifulSoup+Pandas를 이용한 데이터 분석 3 (0) 2021.12.13 웹 크롤링 - BeautifulSoup+Pandas를 이용한 데이터 분석 (0) 2021.12.11 웹 크롤링 - BeautifulSoup 기초 개념 (0) 2021.12.09 BeautifulSoup 03 - Basics of data science tasks (2) - 위키피디아 영화 관련 스크래핑 (0) 2021.12.08 - 판다스의 데이터 프레임을 이용하여 표 세팅