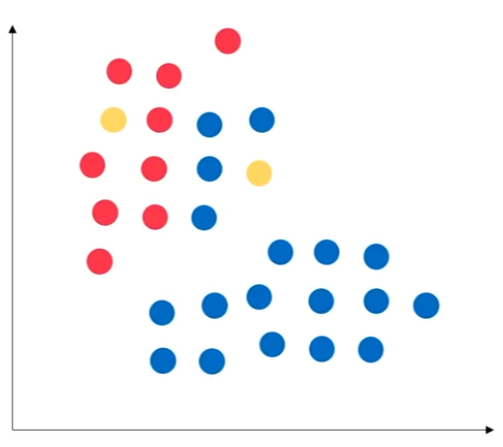
이진 분류에서는 앞선 강의에서 배운것처럼 단순 두개의 클래스로 데이터 분류 모델을 통해 분류를 한다.
하지만 클래스가 없는 경우라면 어떻게 해야 할까? 컴퓨터를 어떻게 이해를 시킬 수 있을까? 사람이 보기에는 대략 2개의 부분으로 나누어져 있는거처럼 보이지만 컴퓨터는 알 수 없다
이런 상황에 쓰기 좋은 분석이 'K-means 군집 분류 분석'이다
주어진 데이터를 k개의 클러스터로 묶는 방식인데 거리 차이의 분산을 최소화 하는 방식으로 수행
여러가지 군집분류방식이 있지만 가장 기본적인 단계가 있다 'Expectation' / 'Maximazation' 단계 이다.
Expectation 단계의 경우는 사람이 정한 군집의 수대로 군집의 중심을 랜덤하게 배치
Maximazation 단계는 찍은 점을 중심으로 가까운것들끼리 속하게 만든다. 그래서 군집을 A/B로 나누게 하는것이 이 단계에서 이루어 진다.
나눠진 군집마다 거리 평균이 있을거고 그 평균을 기준으로 기준점을 다시 잡는다.
이 초기 점과 군집들간의 거리를 재는 방법이 여러가지가 있는데 그 중 가장 기초적인 개념이 '유클리디안 거리'이다. 차원이 많아지거나 복잡해지면 차원축소등 다른 높은 모델을 써야 한다.
02 군집분석 평가
군집분석모델도 평가를 해야한다. 가장 일반적인 비지도 학습 평가 지표가 엘보우 메서드와 실루엣 계수가 있다.
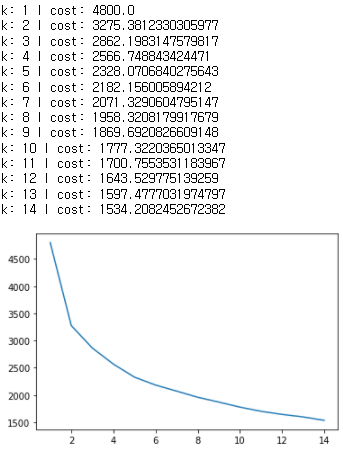
엘보우 메서드를 포문을 돌려서 사용 가능 하다. K값을 변경하면서 '유클리디안' 거리가 현저히 줄어드는 지점을 찾는다. 즉 위의 사진에서는 3개의 군집부터 극격히 줄어드는데 이 뜻은 3개 이상의 군집을 늘려도 대세에는 지장이 없다는 말이다. 즉 3개의 군집이 분류를 하는데 가장 최적화라고 봐도 무방하다.
03 군집분석 실습
from sklearn.cluster import KMeans
x = preprocessed_df[['Attack', 'Defense']] # 2개의 데이터 = 2차원 데이터
# 엘보우 메서드를 위한 리스트
k_list = []
cost_list = []
# 엘보우 메서드를 보기 위한 포문
for k in range(1,6):
kmeans = KMeans(n_clusters=k).fit(x) #군집모델 데이터, 비지도니 y값은 없음
interia = kmeans.inertia_
print('k:', k, 'l cost:',interia)
k_list.append(k)
cost_list.append(interia)
plt.plot(k_list, cost_list);