-
파이썬 활용 09 - 1 - 웹 스크래핑 (Headless/정리/프로젝트)파이썬/파이썬 활용 2021. 11. 9. 20:40
유투버 '나도코딩'님 강의 참조
01 Headless
- 지금까지 Selenium을 써서 스크래핑을 하면 웹을 띄우고 원하는 작업을 하는 등 메모리 + 속도에 차이가 났는데 서버에서 스크래핑을 하게되면 이러한 작업이 필요가 없다.
- Headless 라는 것이 이를 가능하게 해준다. 속도가 원래의 작업보다 훨씬 빠르다

- headless를 쓰는 방법은 간단 하다. 라이브러리를 불러오고 webdriver로 웹을 열때 options를 설정 해주면 된다.
- 그리고 완료되면 스크린샷 기능으로 진행을 남길 수 있다

- Headless를 쓸 때 몇몇의 웹사이트들은 headless를 감지 할 수 있다. 이때도 마찬가지로 UserAgent값을 바꿔서 사용해야 막힘없이 쓸 수 있다.
from selenium import webdriver options = webdriver.ChromeOptions() options.headless = True options.add_argument("window-size=1920x1080") options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36") browser = webdriver.Chrome(options=options) browser.maximize_window() url = "https://www.whatismybrowser.com/detect/what-is-my-user-agent" browser.get(url) detected_value = browser.find_element_by_id("detected_value") print(detected_value.text) browser.quit()
02 정리
- HTML - 뼈대 / CSS - 예쁘게 / JS - 살아 있게
- XPath - element의 정확한 경로 (id/class/text)
- element 간의 관계도 중요 부모-자식
- Chrome을 이용해서 스크래핑/크롤링 해야 개발자 도구로 쉽게 가능
- 정규식 - 규칙을 가진 문자열을 표현하는 식

- User-Agent - 접속하는 유저의 상태를 나타냄 웹페이지는 이에 따라 보여주는 페이지가 다르거나 차단을 함
- Requests - 웹페이지를 읽어오기 위한 기능, 빠르지만 동적 웹페이지에는 적용 불가
- Selenium - 웹페이지 자동화를 위한 기능, 느리지만 동적 웹페이지에 적용 가능
- BeautifulSoup - 위의 두 기능으로 HTML 데이터를 가져와서 원하는 데이터를 추출 가능 하게 함


- 파일 쓰기 및 이미지 다운로드 - with open("파일명", "wb") as f: f.write(res.content)
- CSV 저장 - import csv / f = open(filename, "w", encoding="utf-8-sig", newline="")
- headless - 브라우저를 띄우지 않고 동작
03 미니 프로젝트
- 날씨정보, 헤드라인 뉴스 3건, IT뉴스 3건, 영어 회화 지문 가져오기
- 네이버 오늘의 날씨 가져 오기
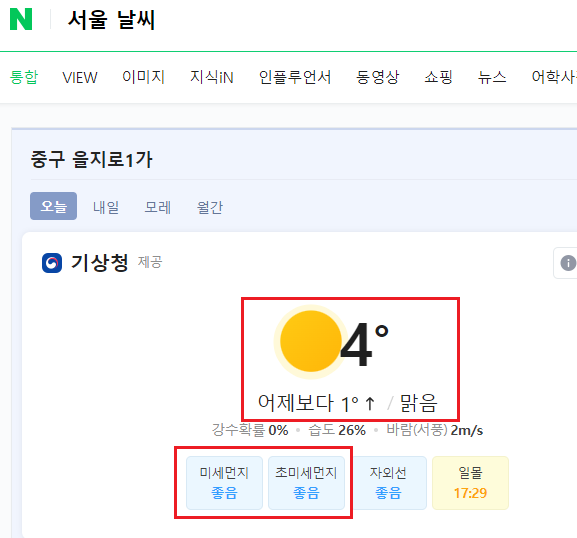

import requests from bs4 import BeautifulSoup def create_soup(url): res = requests.get(url) res.raise_for_status() soup = BeautifulSoup(res.text, 'lxml') return soup def scrape_weather(): print("[오늘의 날씨]") url = "https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=%EC%84%9C%EC%9A%B8+%EB%82%A0%EC%94%A8" soup = create_soup(url) # 맑음, 어제보다 00 높아요 weather = soup.find('span', class_="weather before_slash").get_text() cast = soup.find("p", attrs={'class':'summary'}).get_text().replace("맑음","") # 현재 00도 (최저 00 / 최고 00) curr_temp = soup.find('div', class_='temperature_text').get_text().strip() curr_temp = curr_temp.replace("현재 온도", "현재 온도: ") min_temp = soup.find('span', class_='lowest').get_text().replace("최저기온","최저 기온: ") max_temp = soup.find('span',class_='highest').get_text().replace("최고기온","최고 기온: ") # 강수 확률 moring_rain_rate = soup.select_one('div > div.list_box > ul > li:nth-child(1) > div > div.cell_weather > span:nth-child(1) > span').get_text().strip() afternoon_rain_rate = soup.select_one('div > div.list_box > ul > li:nth-child(1) > div > div.cell_weather > span:nth-child(2) > span').get_text().strip() # 미세 먼지 #똑같은 태그에 여러 클래스가 존재하면 리스트 형식으로 받으면 된다. #클래스, 아이디, 속성 등으로 여러개 찾고 싶을때는 {'class':'', 'id':''} 식으로 찾음 #특정 태그의 특성을 완벽히 찾고 싶으면 {'class':''}, text='' 이런식으로 구분자를 주면 됨 dust = soup.find('ul', class_='today_chart_list') pm10 = dust.find_all('li')[0].get_text().strip().replace("미세먼지", "미세먼지: ") pm25 = dust.find_all('li')[1].get_text().strip().replace("초미세먼지", "초미세먼지: ") print(weather + ", "+cast) print(curr_temp) print(min_temp) print(max_temp) print("강수 확률: " + moring_rain_rate) print("강수 확률: " + afternoon_rain_rate) print(pm10) print(pm25)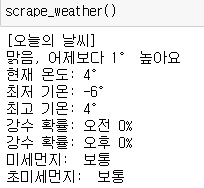
- 네이버 헤드라인 뉴스 들고 오기
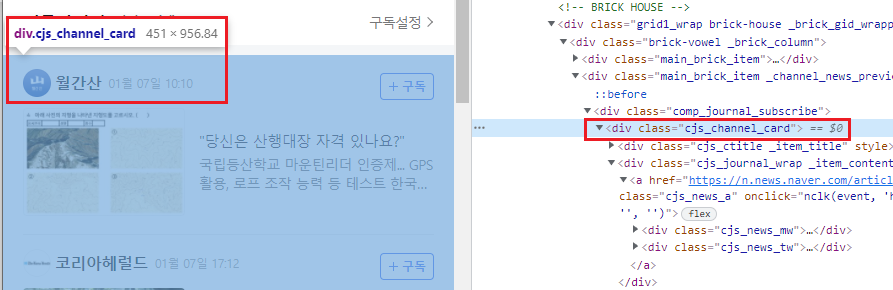
강의상의 네이버와 현재 네이버가 완전히 다르다. 그나마 똑같은 url에 있는 뉴스를 긁어와보자 import requests from bs4 import BeautifulSoup def create_soup(url): res = requests.get(url) res.raise_for_status() soup = BeautifulSoup(res.text, 'lxml') return soup def print_news(index, title, link): print("{}. {}".format(index+1, title)) print("링크 : {}".format(link)) def scrape_headline_news(): print("[최신 뉴스]") url = "https://news.naver.com/" soup = create_soup(url) news = soup.find('div', class_='cjs_channel_card') news_list = news.find_all('div', class_='cjs_journal_wrap _item_contents', limit=3) for index, news in enumerate(news_list): title = news.find('div', class_='cjs_t').get_text().strip() link = news.find('a', class_='cjs_news_a').get('href') print_news(index, title, link) print()
- IT 뉴스 스크래핑

사이트가 약간 바뀌었다! 그래도 긁어보자! def create_soup(url): headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'} res = requests.get(url, headers=headers) res.raise_for_status() soup = BeautifulSoup(res.text, 'lxml') return soup def print_news(index, title, link): print("{}. {}".format(index+1, title)) print("링크 : {}".format(link)) def scrape_it_news(): print("[IT 뉴스]") url = "https://news.naver.com/main/list.naver?mode=LS2D&mid=shm&sid1=105&sid2=230" soup = create_soup(url) news_list = soup.find('ul', class_='type06_headline').find_all('li', limit=3) for index, news in enumerate(news_list): a = news.select('ul.type06_headline > li > dl > dt.photo > a > img') title = a[0].attrs['alt'] link = news.find('a').get('href') print_news(index, title, link) print()
- 영어회화 들고오기

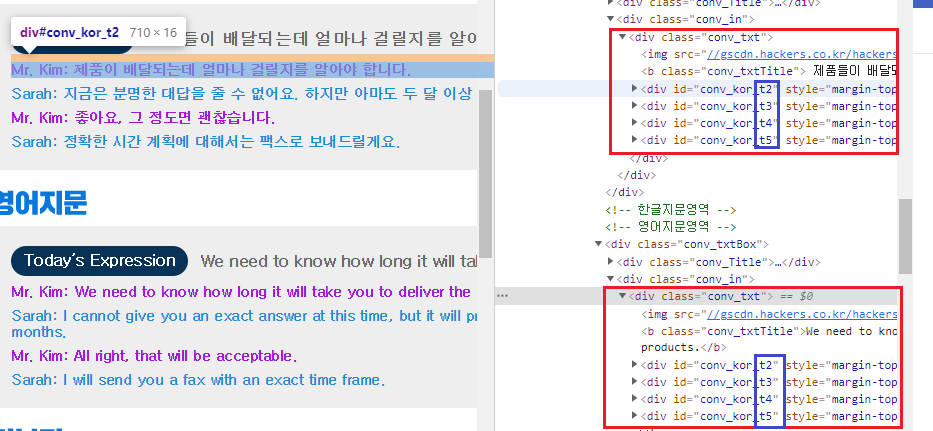
한글 영어 둘다 <div> 태그에 id값은 같으나 마지막 숫자가 바뀌는것을 볼 수 있다. def create_soup(url): headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'} res = requests.get(url, headers=headers) res.raise_for_status() soup = BeautifulSoup(res.text, 'lxml') return soup def print_news(index, title, link): print("{}. {}".format(index+1, title)) print("링크 : {}".format(link)) def scrape_english(): print("[오늘의 영어 회화]") print() url = "https://www.hackers.co.kr/?c=s_eng/eng_contents/I_others_english" soup = create_soup(url) sentences = soup.find_all('div', attrs={'id':re.compile('^conv_kor_t')}) print('- 영어 지문 -') for sentence in sentences[len(sentences)//2:]: # 8문장이라고 가정, 4~7이 영어, 0~3이 한글 print(sentence.get_text().strip()) print() print('- 한글 지문 -') for sentence in sentences[:len(sentences)//2]: print(sentence.get_text().strip()) print()- 이런 경우의 스크래핑을 꼭 알아 두어야 한다
- 일단 애초에 <div> 태그로 한글 / 영어 부분으로 나뉘면서 똑같은 태그와 아이디를 쓰나 마지막 번호에서 갈리는 경우 정규식('^')을 써서 '^--' 으로 시작하는 모든것을 다 찾도록 함 (즉, ^conv_kor_t 로 시작하는 모든 문장을 찾음)
- 이제 개수의 문제인데 어떤날은 짝수 개수의 문장, 어떤날은 홀수 개수의 문장들이 있을수 있으므로 거기에 맞게 for문을 돌려 줘야 한다.
- 즉 영어지문 반, 한글지문 반이라고 볼때 항상 몫으로 세팅을 해주면 몫의값은 항상 반으로 떨어지고 소수점도 '//' 인해 자동으로 처리되어서 7이라도 3개씩 떨어지도록 할 수 있다.
- 영어문장이 반부터 끝까지, 한글문장이 처음부터 반까지 나오도록 돌려 주면 된다

- 완성 코드 (한번에 돌려보기)
더보기import requests
from bs4 import BeautifulSoup
import redef create_soup(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'}
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, 'lxml')
return soup
def print_news(index, title, link):
print("{}. {}".format(index+1, title))
print("링크 : {}".format(link))
def scrape_english():
print("[오늘의 영어 회화]")
print()
url = "https://www.hackers.co.kr/?c=s_eng/eng_contents/I_others_english"
soup = create_soup(url)
sentences = soup.find_all('div', attrs={'id':re.compile('^conv_kor_t')})
# print(len(sentences)//2)
print('- 영어 지문 -')
for sentence in sentences[len(sentences)//2:]: # 8문장이라고 가정, 4~7이 영어, 0~3이 한글
print(sentence.get_text().strip())
print()
print('- 한글 지문 -')
for sentence in sentences[:len(sentences)//2]:
print(sentence.get_text().strip())
print()
def scrape_headline_news():
print("[최신 뉴스]")
url = "https://news.naver.com/"
soup = create_soup(url)
news = soup.find('div', class_='cjs_channel_card')
news_list = news.find_all('div', class_='cjs_journal_wrap _item_contents', limit=3)
for index, news in enumerate(news_list):
title = news.find('div', class_='cjs_t').get_text().strip()
link = news.find('a', class_='cjs_news_a').get('href')
print_news(index, title, link)
print()
def scrape_it_news():
print("[IT 뉴스]")
url = "https://news.naver.com/main/list.naver?mode=LS2D&mid=shm&sid1=105&sid2=230"
soup = create_soup(url)
news_list = soup.find('ul', class_='type06_headline').find_all('li', limit=3)
for index, news in enumerate(news_list):
a = news.select('ul.type06_headline > li > dl > dt.photo > a > img')
title = a[0].attrs['alt']
link = news.find('a').get('href')
print_news(index, title, link)
print()
def scrape_weather():
print("[오늘의 날씨]")
url = "https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=%EC%84%9C%EC%9A%B8+%EB%82%A0%EC%94%A8"
soup = create_soup(url)
# 맑음, 어제보다 00 높아요
weather = soup.find('span', class_="weather before_slash").get_text()
cast = soup.find("p", attrs={'class':'summary'}).get_text().replace("맑음","")
# 현재 00도 (최저 00 / 최고 00)
curr_temp = soup.find('div', class_='temperature_text').get_text().strip()
curr_temp = curr_temp.replace("현재 온도", "현재 온도: ")
min_temp = soup.find('span', class_='lowest').get_text().replace("최저기온","최저 기온: ")
max_temp = soup.find('span',class_='highest').get_text().replace("최고기온","최고 기온: ")
# 강수 확률
moring_rain_rate = soup.select_one('div > div.list_box > ul > li:nth-child(1) > div > div.cell_weather > span:nth-child(1) > span').get_text().strip()
afternoon_rain_rate = soup.select_one('div > div.list_box > ul > li:nth-child(1) > div > div.cell_weather > span:nth-child(2) > span').get_text().strip()
# 미세 먼지
#똑같은 태그에 여러 클래스가 존재하면 리스트 형식으로 받으면 된다.
#클래스, 아이디, 속성 등으로 여러개 찾고 싶을때는 {'class':'', 'id':''} 식으로 찾음
#특정 태그의 특성을 완벽히 찾고 싶으면 {'class':''}, text='' 이런식으로 구분자를 주면 됨
dust = soup.find('ul', class_='today_chart_list')
pm10 = dust.find_all('li')[0].get_text().strip().replace("미세먼지", "미세먼지: ")
pm25 = dust.find_all('li')[1].get_text().strip().replace("초미세먼지", "초미세먼지: ")
print(weather + ", "+cast)
print(curr_temp)
print(min_temp)
print(max_temp)
print("강수 확률: " + moring_rain_rate)
print("강수 확률: " + afternoon_rain_rate)
print(pm10)
print(pm25)
if __name__ == "__main__":
scrape_weather()
print()
scrape_headline_news()
print()
scrape_it_news()
print()
scrape_english()'파이썬 > 파이썬 활용' 카테고리의 다른 글
파이썬 활용 08 - 4 - 웹 스크래핑 (Selenium - 구글 무비) (0) 2021.11.08 파이썬 활용 08 - 3 - 웹 스크래핑 (Selenium - 네이버 로그인) (0) 2021.11.05 파이썬 활용 08 - 2 - 웹 스크래핑 (Selenium) (0) 2021.11.05 파이썬 활용 08 - 1 - 웹 스크래핑 (CSV - 네이버 금융) (0) 2021.11.05 파이썬 활용 07 - 3 - 웹 스크래핑 (BeautifulSoup4 - 다음) (0) 2021.11.05