빅데이터/Machine-Learning
유형별 데이터 분석 맛보기 02 - EDA & 회귀분석(3)
H-V
2022. 2. 16. 16:47
패스트캠퍼스 '직장인을 위한 파이썬 데이터분석 올인원 패키치 Online' 참조
- 보스턴 데이터셋으로 회귀분석이 어떻게 쓰이는지를 알아 보자!
01 데이터 전처리
- 피처들의 회귀분석에 적합하게 만들어야 한다. 피처들의 단위 표준화가 필요하다
- 예로 아래 그래프를 보면 각각의 피처들의 값이 우후죽순이다.
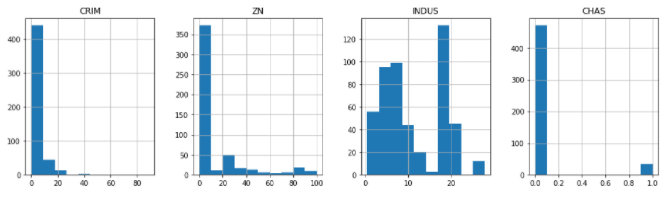
CRIM = 0~80, ZN=0~100, INDUS=0~20, CHAS=0.0~1.0 - 'Sklearn' 패키지를 훑어볼때 배웠던 'Scaler'로 하면 된다.
- 여기서 Scaler는 중고등학교때 배웠던 'z'값(표준화) 구하기가 반영된 패키지다. z값 수치로 표본들이 평균으로부터 몇 구간의 표준 편차만큼 떨어져 있는지 알려주는 값 (Scaler를 하게되면 평균 0 을 기준으로 표준편차 -2~2 내외로 세팅됨)
# 1. 데이터 전처리 - 피처들의 단위 표준화
from sklearn.preprocessing import StandardScaler
# feature standardization
scaler = StandardScaler()
# 타겟값을 제외하고 표준화를 하고자 하는 컬럼들을 변수화
scale_columns = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM' , 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
# DF에 새롭게 컬럼을 추가하여 적용하는데 적용되는 값은 scaler가 들어간 값이 들어가도록 함
df[scale_columns] = scaler.fit_transform(df[scale_columns])

▶ 데이터가 이제 사용될 수 있도록 표준화가 진행이 되었으면 회귀분석의 지도학습을 위한 데이터셋을 분리를 해줘야 한다.
# 데이터셋 분리
from sklearn.model_selection import train_test_split
# x = feautre 학습 데이터
# y = 예측값
x = df[scale_columns]
y = df['CMEDV']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=33)
x_train.shape
(404, 13)
▶ 전 시간에 공부했던대로 쉽게 말해 데이터셋을 분리하고 분리된 train데이터로 학습을 시킨다 (x-문제,y-답 을 던져주고 학습을 시킴)
# 데이터 학습
from sklearn import linear_model
from sklearn.metrics import mean_squared_error # 모델 평가용
from math import sqrt
# train regression model
lr = linear_model.LinearRegression() # 사용하고자 하는 모델을 불러와 변수화
model = lr.fit(x_train, y_train) # 그리고 문제와 정답지를 주고 학습을 시킴
print(lr.coef_)
[-0.95549078 1.18690662 0.22303997 0.76659756 -1.78400866 2.83991455
-0.05556583 -3.28406695 2.84479571 -2.33740727 -1.77815381 0.79772973
-4.17382086]- .coef_를 통해서 이 모델의 w/b가 어떻게 학습 됬는지 볼 수 있다. 'Y=wX+b'가 성립이 되어 13개의 x에 대한 y값이 .나온다
▶ 학습 계수를 그래프로 확인!
# 학습 계수를 그래프로 확인
# 이유는 학습한 w들이 어떤 피처에서 어떤 영향이 있는지 볼 수 있음
# 예로, 1번은 양의 상관정도가 나오고 2번은 음수에 가깝다는 등을 그래프로 볼 수 있음
# .rcParams
plt.rcParams['figure.figsize'] = [12,16]
coefs = lr.coef_.tolist() # .coef_로 받아온 데이터를 .tolist() = 파이썬 리스트 형식으로 바꿔줌
coefs_series = pd.Series(coefs) # 판다스/넘파이로 출력하기 위해 시리즈로 변환
x_labels = scale_columns
ax = coefs_series.plot.barh() # 그래프 세팅을 위해 변수화
ax.set_title('Feature Coef Graph')
ax.set_xlabel('coef')
ax.set_ylabel('x_features')
ax.set_yticklabels(x_labels); # 눈금 이름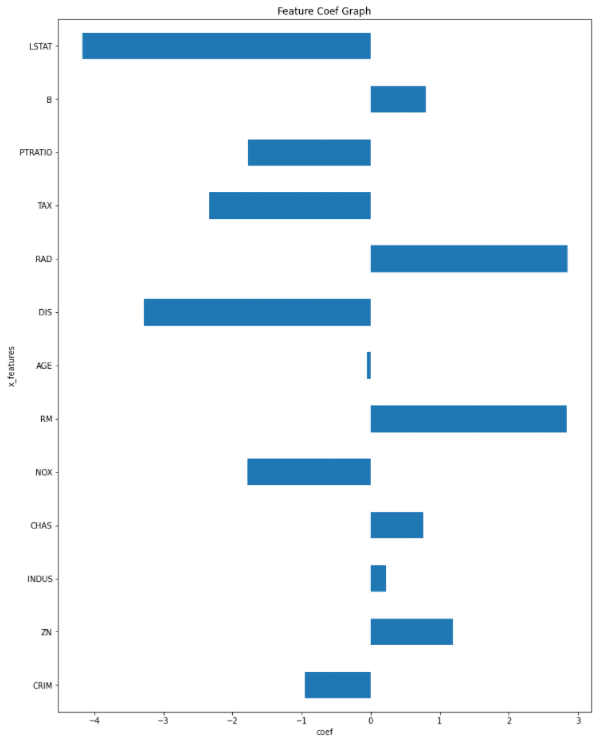
- 시각화 관련 블로그 (https://zzsza.github.io/development/2018/08/24/data-visualization-in-python/)
- 시리즈화 관련 링크 (https://wikidocs.net/4364#:~:text=pandas%EC%9D%98%20Series%EB%8A%94%20%EC%82%AC%EC%8B%A4,Series%20%EA%B0%9D%EC%B2%B4%EB%A5%BC%20%EC%83%9D%EC%84%B1%ED%95%B4%EC%A4%8D%EB%8B%88%EB%8B%A4.&text=Series%20%EA%B0%9D%EC%B2%B4%EB%A5%BC%20%EC%83%9D%EC%84%B1%ED%95%A0,%EC%A0%95%EC%88%AB%EA%B0%92%EC%9C%BC%EB%A1%9C%20%EC%9D%B8%EB%8D%B1%EC%8B%B1%EB%90%A9%EB%8B%88%EB%8B%A4.)
02 학습 결과 해석
- 회귀분석과 같은 예측 모델에서는 'R2 Score'/'RMSE Score'를 많이 사용
1) R2 Score (결정 계수)
# 학습 결과 해석
print(model.score(x_train, y_train))
0.7490284664199387
print(model.score(x_test, y_test))
0.700934213532155- 1에 가까울수록 모델의 성능이 좋다 즉 예측을 잘 한다는 말
- 훈련에서는 75점, 실제 예측에서는 70점에 가까운 예측을 함.
2) RMSE Score - MSE에 루트를 씌운 값. 예측값과 실제값의 차이가 적을수록 좋음
# RMSE Score
y_predictions = lr.predict(x_train) # x문제집을 던져주고 거기에 답을 예측하도록 함
print(sqrt(mean_squared_error(y_train, y_predictions))) # 실제 답과 예측 답을 비교하여 수치로 나타냄
# RMSE Score
y_predictions = lr.predict(x_test) # x문제집을 던져주고 거기에 답을 예측하도록 함
print(sqrt(mean_squared_error(y_test, y_predictions))) # 실제 답과 예측 답을 비교하여 수치로 나타냄
4.672162734008588
4.614951784913309- 실제 = 4.67, 예측 4.61 차이가 많이 없으므로 모델의 성능이 좋다고 볼 수 있음
03 유의성과 다중 공선성
# 피처 유의성 검성
import statsmodels.api as sm
x_train = sm.add_constant(x_train)
model = sm.OLS(y_train, x_train).fit()
model.summary()
- 회귀분석 결과 해석시에는 결정계수확인 → 모형의 적합도 확인 → 회귀계수확인 → t값/유의확률 확인
- 결정계수가 0.749로써 1에 가깝다. 나쁘지 않은 모델
- F값이 0에 가까울수록 도출된 회귀식이 적절하다고 볼 수 있음
- Prob(F-statistics) - 회귀식이 유의미한지 판단. 0.05이하일 경우 변수 끼리 매우 관련있다고 판단 (현재는 0)
- P>ltl - 독립변수들의 유의확률, 0.05보다 작아야 유의미한 관계를 가지고 있다고 할 수 있음.
- 쉽게 말해 P값이 0에 가까울수록 회귀식이 유의하다고 볼 수 있고 F값이 높아질수록 P값은 낮아진다고 한다. F값 89는 상당히 높은값이라 P값은 0에 가깝게 나왔고 따라서 회귀식 자체는 유의
- 즉 INDUS/AGE 변수는 무의미하기때문에 다음에는 제거를 하고 돌려야 성능이 더 잘나옴.
- 이제 표를 해석하자면 집값을 예측할때 집값에 영향을 주는 피처들은 INDUS/AGE를 제외하고 대부분이 다 영향을 준다는것을 알 수 있다
참고 링크 - https://ysyblog.tistory.com/119
[회귀분석] 회귀분석 실습(1) - OLS 회귀분석 결과 해석 및 범주형 변수 처리 (Statsmodel)
Statsmodel을 활용한 회귀분석 statsmodels 패키지에서는 OLS 클래스를 사용하여 선형 회귀분석을 실시한다 독립변수와 종속변수가 모두 포함된 데이터프레임이 생성되며, 상수항 결합은 하지 않아도
ysyblog.tistory.com
- 다중공산성 -
# 다중공산성
from statsmodels.stats.outliers_influence import variance_inflation_factor
vlf = pd.DataFrame()
vlf['VIF Factor'] = [variance_inflation_factor(x_train.values, i) for i in range(x_train.shape[1])]
vlf['Feature'] = x_train.columns
vlf.round(1)
- 제거기준은 10이상이기때문에 다중공산성의 문제는 없어 보인다.
- 정리를 하자면 회귀분석은 '예측'을 하는 모델인데 여기서의 예측은 2023년 이 집값의 가격은? 이런 예측이 아니다
- 지금까지 해왔던 프로세스를 되짚어 보면 집값이라는 피처에 다른 피처들을 대입시켜 특정조건에 이런 집값이 나온다라는것을 '예측'하는게 회귀분석인 것이다. 예로 방6개면 가격이 이정도 일거다 라고 예측을 할 수 있는것이다.