빅데이터/Selenium
Selenium 기초 및 활용 하기 02 - 네이버웹툰 스크래핑
H-V
2022. 1. 10. 20:51
유투버 '이수안컴퓨터연구소' 강의 참조
01 셀레니엄 VS 뷰티풀숩
- 현재 크롤링 공부를 하면서 뷰티풀숩을 먼저 공부하고 이제 셀레니움으로 넘어왔는데 왜 두개가 대표적으로 사용되는 라이브러리인지가 궁금해졌다.
- 크롤링에 앞서 두 가지 라이브러리가 가장 '대표적' 으로 쓰인다
- 현재 2022년을 기준으로 웹사이트 특징들을 보면 대부분 동적인 웹사이트들이 주로 이루어진다. 즉 예전 인터넷이 막나왔을때의 웹사이트처럼 정적이 아닌 사이트에 들어가보면 페이지를 새로고침 없이 페이지가 바뀐다던지 혹은 가만히 있어도 웹페이지가 업데이트가 된다던지의 특징이 있다. 즉 이러한 동적 페이지는 HTML/CSS/JS가 기본이되어 사용자의 요청에 해당하는 저장이 되어진 페이지만 보냈었다면 현재는 동적 웹페이지로서 사용자의 요청을 해석하여 데이터를 가공한 후 생성이 되는 페이지를 보내기때문에 새로고침없이 페이지가 계속해서 업데이트 될 수 가 있는 것이다.
- 그럼 왜 두개를 나눠서 쓸까?
- 가장 큰 특징은 셀레니엄은 현재 스크롤링보다는 자동화 테스트에 사용되는 프레임 워크(웹페이지를 완성 후 배포하기전에 주로 셀레니엄으로 테스트를 한다고 알려짐)인데 이 자동화를 통해서 버튼을 클릭한다던지, 스크롤링을 한다는지 등의 행동을 코드를 통해 사용자가 일일히 할 필요가 없게 도와주는 도구 이다.
- 뷰티풀숩은 파이썬에 내장된 라이브러리인데 동적인 웹페이지 크롤링시에 처음 나오는 데이터들만 크롤링이 되는 단점이 있다. 즉 HTML/XML 파일의 정보만을 추출해낼 수 있다. 스크래핑/크롤링시에 서버의 HTML을 다운받기때문에 렌더링이나 다운이 되지 않은 정보, 시간이 흐르면서 계속해서 업데이트 되는 정보들 등을 가져 올 수 없는 것이다.
- 이 단점을 셀레니움을 통해서 해결이 가능한 것이다. 셀레니움은 JS를 통해 렌더링되고 뒤 늦게 업데이트 되는 데이터들을 손쉽게 가져 올 수 있다. 단순 HTML을 가져오는게 아닌 웹페이지 전부를 가져올 수 있다고 보면 된다.
- 셀레니움이 뷰티풀숩보다 당연히 속도도 많이 느리고 메모리도 많이 차지하게 된다.
02 네이버 웹툰 스크래핑 시작하기
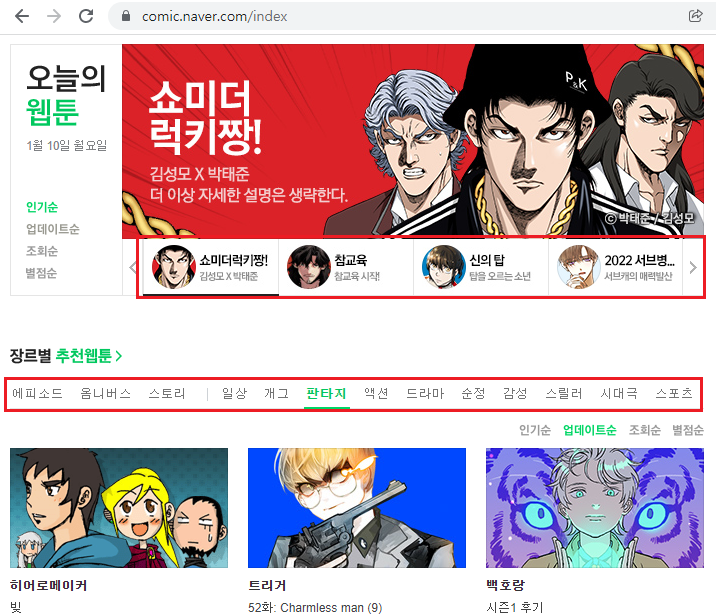
- 위에서 설명한 대로 이러한 동적 웹사이트들은 새로고침없이 빨간색 박스안에있는 탭들만 클릭하면 계속해서 정보가 바뀌거나 업데이트가 되는것을 볼 수 있는데 이러한 정보들은 뷰티풀숩으로 접근하기에는 한계가 있다.
- 셀레니움을 써서 자동화를 기반으로 마치 사람이 클릭을하고 거기에 대한 소스를 얻고 접근을하여 데이터를 가져온다고 보면 되는 것.
* 기본 세팅
import selenium
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#웹브라우저를 띄우지 않고 진행하기 위한 설정
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
#이렇게 객체를 생성하여 위에서 세팅된 값을 넣어주면 된다!
wd = webdriver.Chrome('chromedriver', options=chrome_options)
02 첫번째 데이터
1. 타이틀 시도

for title in wd.find_elements_by_class_name('title'):
print(title.text)
*
titles = wd.find_elements_by_class_name('title')
for title in titles:
print(title.text)
▶ 빨간색 오류(?)는 아래와 같이 'By'를 사용하면 해결 가능 하다.
for title in wd.find_elements(By.CLASS_NAME, 'title'):
print(title.text)
- 2가지의 이슈가 있다. '컷툰'이 같이 출력 되는 것. 또한 다른 탭 데이터도 들고 와 바야 하는 것.

03 Second Task
- 탭 부분 처리

g_tags = wd.find_element(By.CLASS_NAME, 'tab_gr') #전체 탭 태그 접근
genres = g_tags.find_elements(By.TAG_NAME, 'a') #거기서 탭을 옮겨다닐 <a> 태그 긁어옴
for genre in genres:
genre.click() # 실제로 자동화 라이브러리로 클릭이 가능 (.click())
print('[', genre.text,']')
- 각 탭부분에 맞는 타이틀 스크래핑

- 작가까지 같이!

g_tags = wd.find_element(By.CLASS_NAME, 'tab_gr') #전체 탭 태그 접근
genres = g_tags.find_elements(By.TAG_NAME, 'a') #거기서 탭을 옮겨다닐 <a> 태그 긁어옴
for genre in genres:
genre.click() # 실제로 자동화 라이브러리로 클릭이 가능 (.click())
print('[', genre.text,']')
time.sleep(1)
#타이틀을 하나 클릭하고 이 밑에부분이 실행 되는 것!
genre_rec_list = wd.find_elements(By.CLASS_NAME, 'genreRecomInfo2')
for genre_rec in genre_rec_list:
title_class = genre_rec.find_element(By.CLASS_NAME, 'title')
title = title_class.find_element(By.TAG_NAME, 'a').text
user = genre_rec.find_element(By.CLASS_NAME, 'user').text
print('\t', title, '-', user)- time.sleep()을 통해서 포문을 돌려줘야 오류 없이 스크래핑이 된다. 동적인 페이지는 사람의 속도로 열리지 않기때문에 time.sleep()없이는 엘리멘트를 못찾는 오류를 띄운다.
- time.sleep() 의 위치가 중요 하다. 어디서 탭 혹은 사이트가 열리는지 잘 보고 위치를 반영 해야 한다.
