카테고리 없음
파이썬 활용 10 - 2 - 웹 스크래핑 (개요 및 패키지 활용)
H-V
2021. 12. 9. 12:03
- 웹 스크래핑시에는 Python의 'BeautifulSoup' 라이브러리를 활용
01 HTML 파싱
- BeautifulSoup을 사용하여 HTML문서를 파싱. 파싱 이후 태그를 끌어와서 스크래핑 가능
- 파서 라이브러리는 4가지가 있는데 주로 'html.parser' or 'lxml' 을 많이 씀
- HTML문서의 태그들에 접근시에는 <html>,<head>,<body>태그는 제외하고 접근하는게 좋음
- 태그명 + '.' 연산자를 함께 사용
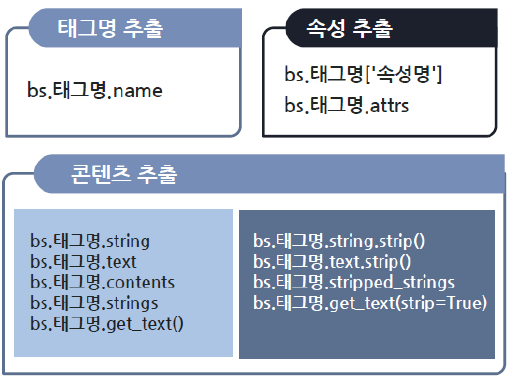
- 태그들 간의 연관관계도 이해를 해야함

- 간단 실습
from bs4 import BeautifulSoup
html_doc = """
<!DOCTYPE html>
<html>
<head>
<meta charset="utf
8">
<title>Test BeautifulSoup</title>
</head>
<body>
<h1>
테스트 </
</body>
</html> """
bs = BeautifulSoup(html_doc, 'html.parser')
print(type(bs)
<class 'bs4.BeautifulSoup'>from bs4 import BeautifulSoup
html_doc = """
<!DOCTYPE html>
<html>
<head>
<meta charset='utf-8'>
<title>Test BeautifulSoup</title>
</head>
<body>
<p align="center">P 태그의 컨텐트 </p>
<img src="http://unico2013.dothome.co.kr/image/flower.jpg" width="300">
</body>
</html> """
bs = BeautifulSoup(html_doc, 'html.parser')
print(bs.prettify())
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8"/>
<title>
Test BeautifulSoup
</title>
</head>
<body>
<h1>
테스트
<!--
</body-->
</h1>
</body>
</html>html_doc = """
<!DOCTYPE html>
<html>
<head>
<meta charset='utf
8'>
<title>Test BeautifulSoup</title>
</head>
<body>
<p align="center">P 태그의 컨텐트 </p>
<img src="http://unico2013.dothome.co.kr/image/flower.jpg" width="300">
<ul>
<li>
테스트 1<strong> 강조 </strong></li>
<li>
테스트 2</li>
<li>
테스트 3</li>
</ul>
</body>
</html> """
bs = BeautifulSoup(html_doc, 'html.parser')
print(type(bs.title), ':', bs.title)
print(type(bs.title.name),':', bs.title.name)
print(type(bs.title.string),':', bs.title.string)
print('-------------------------------------------')
print(type(bs.p['align']),':', bs.p['align'])
print(type(bs.img['src']),':', bs.img['src'])
print(type(bs.img.attrs),':', bs.img.attrs)
print("[ string 속성 ]")
print(bs.p.string)
print(bs.ul.string)
print(bs.ul.li.string)
print(bs.ul.li.strong.string)
print("[ text 속성 ]")
print(bs.p.string)
print(bs.ul.text)
print(bs.ul.li.text)
print(bs.ul.li.strong.text)
print("[ contents 속성 ]")
print(bs.p.contents)
print(bs.ul.contents)
print(bs.ul.li.contents)
print(bs.ul.li.strong.contents)
02 웹상에서 파싱
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://stackoverflow.com")
bs = BeautifulSoup(html.read(), 'html.parser')
print(bs.title)
print()
print(bs.title.text)
print()
print(bs.h1)
print()
print(bs.h1.text)
print()
print(bs.span)
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = """
<html><body>
<h1>Hello python</h1>
<p>웹 페이지 분석 </p>
<p>웹 스크래핑 </p>
</body></html>
"""
soup = BeautifulSoup(html, 'html.parser')
h1 = soup.html.body.h1
p1 = soup.html.body.p
p2 = p1.next_sibling.next_sibling
print("h1=",h1)
print("h1=",h1.string)
print("p=",p1)
print("p=",p1.string)
print("p=",p2)
print("p=",p2.string)
h1= <h1>Hello python</h1>
h1= Hello python
p= <p>웹 페이지 분석 </p>
p= 웹 페이지 분석
p= <p>웹 스크래핑 </p>
p= 웹 스크래핑- 변수화(soup)를 통해 웹상의 HTML 내용을 담고 그 내용안에서 '.' 연산자를 이용하여 각각의 태그에 접근 가능
- 앞서 언급했듯이 각 태그의 연관성을 알면 반복되는 <p> 태그일지라도 접근이 가능
- 각 태그의 이름으로 불러오거나 태그들의 속성을 통해서도 불러 올 수 있다.
02 - 1 웹상에서의 파싱 2
- BeautifulSoup의 라이브러리 중 강력한 기능들을 몇가지 알아 보자.
find_all - 주어진 기준에 맞는 모든 태그들을 찾아 옴 *결과는 bs4.element.ResultSet 객체로 리턴
find - 주어진 기준에 맞는 태그 한개를 찾아 옴 *결과는 bs4.element.Tag 객체로 리턴
select - 주어진 CSS 선택자에 맞는 모든 태그를 찾아 옴 *결과는 list 객체로 리턴 - HTML 문서는 트리구조 형식의 DOM형태인데 이 DOM형태들을 각각의 객체로 나누어서 속성으로 접근이 가능
- 간단 실습
from urllib.request import urlopen
from bs4 import BeautifulSoup as bs
html = """
<html>
<body>
<h1 id="title">Hello python</h1>
<p id="body"> 웹 페이지 분석 </p>
<p> 웹 스크래핑 </p>
<span> 데이터 수집 1</span>
<span> 데이터 수집 2</span>
</body>
</html>
"""
soup = bs(html, 'html.parser')
title = soup.find(id='title')
body = soup.find(id='body')
span = soup.find('span')
print('#title = ', title)
print('#title = ' + title.string)
print('#body = ', body)
print('#body = ', body.string)
print('#span = ', span.string)
#title = <h1 id="title">Hello python</h1>
#title = Hello python
#body = <p id="body"> 웹 페이지 분석 </p>
#body = 웹 페이지 분석
#span = 데이터 수집 1- 태그의 속성들이 없다면 위에서 하는 방법처럼 쉽게 찾을 수 있겠지만 보통 웹페이지는 그렇지 않다. 많은 HTML 내용과 CSS/JS 등으로 구성되어있기 때문에 태그의 속성으로 찾는것이 훨씬 편하다.
from urllib.request import urlopen
from bs4 import BeautifulSoup as bs
html_doc = """
<!DOCTYPE html>
<html>
<head>
<meta charset='utf8'>
<title>Test BeautifulSoup</title>
</head>
<body>
<p align="center"> text contents </p>
<p align="right"> text contents 2 </p>
<p align="left"> text contents 3 </p>
<img src="http://unico2013.dothome.co.kr/image/flower.jpg" width="500">
<div>
<p>text contents 4</p>
</div>
</body>
</html>
"""
bs = BeautifulSoup(html_doc, 'html.parser')
print(type(bs.find('p')))
print(type(bs.find_all('p')))
print("-----------------------------")
print(bs.find('title'))
print(bs.find('p')) # 가장 첫 번째 '<p>'를 들고 옴
print(bs.find('img'))
print("-----------------------------")
ptags = bs.find_all('p')
print(ptags)
print("-----------------------------")
for tag in ptags:
print(tag)
<class 'bs4.element.Tag'>
<class 'bs4.element.ResultSet'>
-----------------------------
<title>Test BeautifulSoup</title>
<p align="center"> text contents </p>
<img src="http://unico2013.dothome.co.kr/image/flower.jpg" width="500"/>
-----------------------------
[<p align="center"> text contents </p>,
<p align="right"> text contents 2 </p>,
<p align="left"> text contents 3 </p>, <p>text contents 4</p>]
-----------------------------
<p align="center"> text contents </p>
<p align="right"> text contents 2 </p>
<p align="left"> text contents 3 </p>
<p>text contents 4</p>