파이썬/파이썬 활용
파이썬 활용 07 - 2 - 웹 스크래핑 (BeautifulSoup4 - 쿠팡)
H-V
2021. 11. 4. 20:04
유투버 '나도코딩'님 강의 참조
01 BeautifulSoup4 활용 2
- 이번에는 쿠팡을 스크래핑 해보자

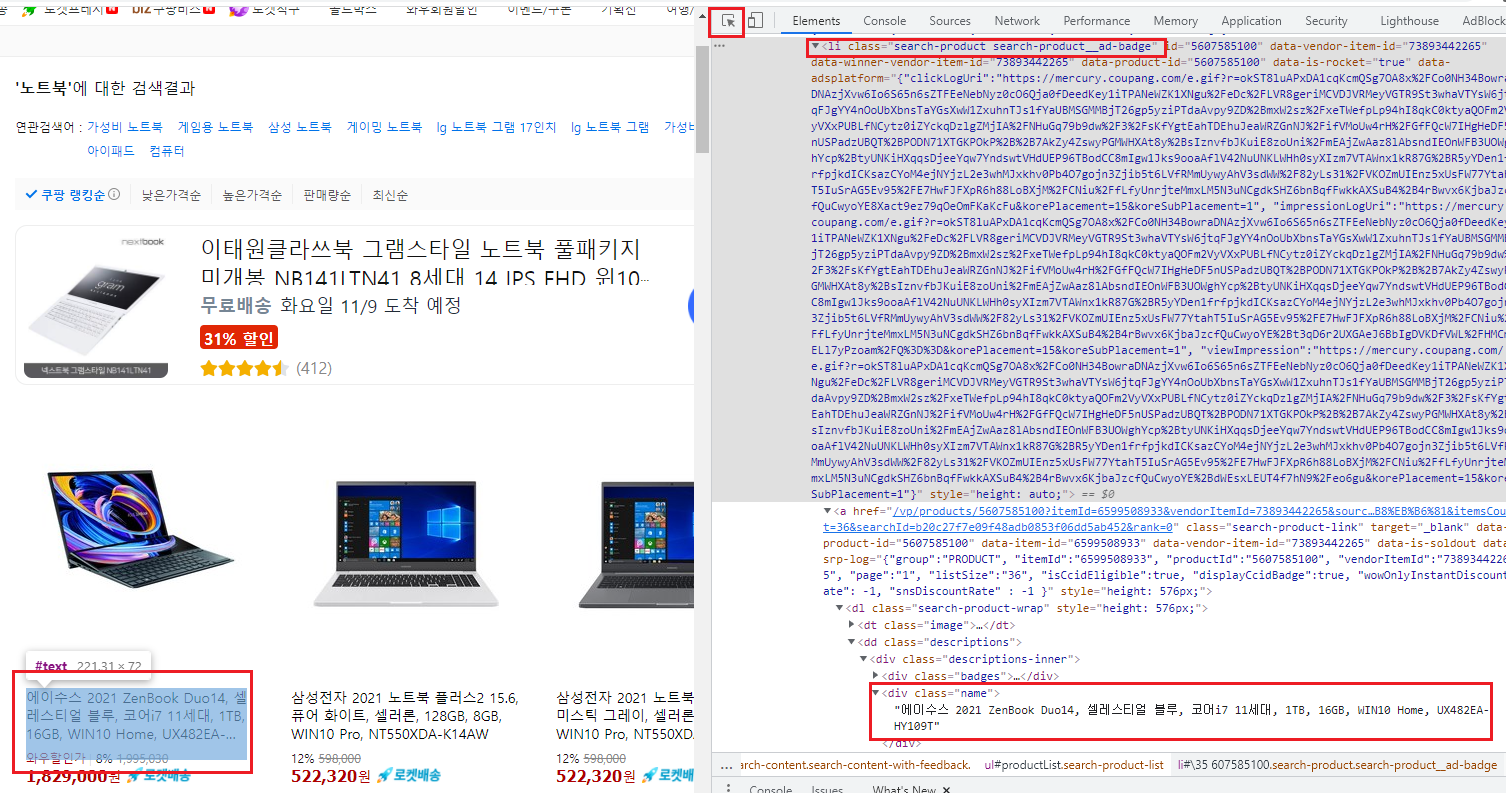
- 정규식을 써서 쿠팡의 제품 이름들을 가져와 보자
- 스크래핑을 진행하려고하니 쿠팡에서 차단을 한거 같다. User Agent를 변경해서 사람이 직접 보는것처럼 변경해서 접근 해 보자!
import requests
import re
from bs4 import BeautifulSoup
url ="https://www.coupang.com/np/search?q=%EB%85%B8%ED%8A%B8%EB%B6%81&channel=user&component=&eventCategory=SRP&trcid=&traid=&sorter=scoreDesc&minPrice=&maxPrice=&priceRange=&filterType=&listSize=36&filter=&isPriceRange=false&brand=&offerCondition=&rating=0&page=1&rocketAll=false&searchIndexingToken=1=6&backgroundColor="
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"}
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
items = soup.find_all("li", attrs={"class":re.compile("^search-product")})
print(items[0].find("div", attrs={"class":"name"}).get_text())
에이수스 2021 ZenBook Duo14, 셀레스티얼 블루, 코어i7 11세대, 1TB, 16GB, WIN10 Home, UX482EA-HY109T- 응용해서 이름/가격/평점/리뷰수를 한번에 들고 와 보자
- 가격

- 평점

- 리뷰 수

import requests
import re
from bs4 import BeautifulSoup
url ="https://www.coupang.com/np/search?q=%EB%85%B8%ED%8A%B8%EB%B6%81&channel=user&component=&eventCategory=SRP&trcid=&traid=&sorter=scoreDesc&minPrice=&maxPrice=&priceRange=&filterType=&listSize=36&filter=&isPriceRange=false&brand=&offerCondition=&rating=0&page=1&rocketAll=false&searchIndexingToken=1=6&backgroundColor="
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"}
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
items = soup.find_all("li", attrs={"class":re.compile("^search-product")})
# print(items[0].find("div", attrs={"class":"name"}).get_text())
for item in items:
name = item.find("div", attrs={"class":"name"}).get_text()
price = item.find("strong", attrs={"class":"price-value"}).get_text()
ratings = item.find("em", attrs={"class":"rating"})
if ratings:
ratings = ratings.get_text()
else:
ratings = "No ratings"
reviews = item.find("span", attrs={"class":"rating-total-count"})
if reviews:
reviews = reviews.get_text()
else:
reviews = "No reviews"
print(name, price, ratings, reviews)- 데이터가 없는부분은 'if'문으로 나눠서 처리 해줘야 한다.

- 광고가 들어간 제품은 제외하고 데이터를 들고 오자(광고는 쿠팡에서 미는 제품이기때문에 스크래핑해서 정보를 모으는데 별로 좋지 않다)

for item in items:
#광고 제품 제외
ad_badge = item.find("span", attrs={"class":"ad-badge-text"})
if ad_badge:
print("광고 상품 제외!")
continue
- 특정 조건으로 스크래핑 하기
for item in items: # 광고 제품은 제외 ad_badge = item.find("span", attrs={"class":"ad-badge-text"}) if ad_badge: print(" <광고 상품 제외합니다>") continue name = item.find("div", attrs={"class":"name"}).get_text() # 제품명 # 애플 제품 제외 if "Apple" in name: print(" <Apple 상품 제외합니다>") continue price = item.find("strong", attrs={"class":"price-value"}).get_text() # 가격 # 리뷰 100개 이상, 평점 4.5 이상 되는 것만 조회 rate = item.find("em", attrs={"class":"rating"}) # 평점 if rate: rate = rate.get_text() else: print(" <평점 없는 상품 제외합니다>") continue rate_cnt = item.find("span", attrs={"class":"rating-total-count"}) # 평점 수 if rate_cnt: rate_cnt = rate_cnt.get_text() # 예 : (26) rate_cnt = rate_cnt[1:-1] #print("리뷰 수", rate_cnt) else: print(" <평점 수 없는 상품 제외합니다>") continue if float(rate) >= 4.5 and int(rate_cnt) >= 100: print(name, price, rate, rate_cnt)

- 여러 페이지 스크래핑
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"}
for i in range(1, 6):
print("현재 페이지: ", i)
url = "https://www.coupang.com/np/search?q=%EB%85%B8%ED%8A%B8%EB%B6%81&channel=user&component=&eventCategory=SRP&trcid=&traid=&sorter=scoreDesc&minPrice=&maxPrice=&priceRange=&filterType=&listSize=36&filter=&isPriceRange=false&brand=&offerCondition=&rating=0&page={}&rocketAll=false&searchIndexingToken=1=4&backgroundColor=".format(i)
res = requests.get(url, headers=headers)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
items = soup.find_all("li", attrs={"class":re.compile("^search-product")})
for item in items:
# 광고 제품은 제외
ad_badge = item.find("span", attrs={"class":"ad-badge-text"})
if ad_badge:
# print(" <광고 상품 제외합니다>")
continue
name = item.find("div", attrs={"class":"name"}).get_text() # 제품명
# 애플 제품 제외
if "Apple" in name:
# print(" <Apple 상품 제외합니다>")
continue
price = item.find("strong", attrs={"class":"price-value"}).get_text() # 가격
# 리뷰 100개 이상, 평점 4.5 이상 되는 것만 조회
rate = item.find("em", attrs={"class":"rating"}) # 평점
if rate:
rate = rate.get_text()
else:
# print(" <평점 없는 상품 제외합니다>")
continue
rate_cnt = item.find("span", attrs={"class":"rating-total-count"}) # 평점 수
if rate_cnt:
rate_cnt = rate_cnt.get_text()[1:-1] # 예 : (26)
else:
# print(" <평점 수 없는 상품 제외합니다>")
continue
link = item.find("a", attrs={"class":"search-product-link"})["href"]
if float(rate) >= 4.5 and int(rate_cnt) >= 100:
print(f"제품명 : {name}")
print(f"가격 : {price}")
print(f"평점 : {rate}점 ({rate_cnt}개)")
print("바로가기 : {}".format("https://www.coupang.com"+link))
print("-"*10)