BeautifulSoup4 을 사용하기 위해서 2가지를 설치를 해줘야 한다!
beautifulsoup4 - 실제로 스크래핑을 위한 패키지 lxml - lxml은 스크래핑시 구문들을 파싱하기 위한 패키지
간단 테스트 (네이버 웹툰)
import requests
from bs4 import BeautifulSoup
url ="https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status()
#URL을 통해 가져온 HTML문서를 'lxml'을 통해 파싱을 하고 객체로 만듬
soup = BeautifulSoup(res.text, "lxml")
print(soup.title)
'res' 변수에 requests.get(url) 정보를 담음 (HTML 형식으로 담김)
'soup' 변수에 BeautifulSoup 을 이용한 res.text(HTML)를 스크래핑, 파싱은 'lxml'로 진행
스크래핑 + 파싱이 되었으니 soup 변수를 통해 내용들을 가져올 수 있음
*여러가지를 가져와보자
import requests
from bs4 import BeautifulSoup
url ="https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status()
#URL을 통해 가져온 HTML문서를 'lxml'을 통해 파싱을 하고 객체로 만듬
soup = BeautifulSoup(res.text, "lxml")
# print(soup.title)
# print(soup.title.get_text())
# print(soup.a)
# print(soup.a.attrs)
print(soup.a["href"])
위의 같은 정확한 파싱은 그 웹사이트에대한 정확한 이해가 있으면 가능하나 보통 웹 스크래핑시에는 어렵다. 그래서 웹의 상태를 잘 모를때 쓸 수 있는 '.find()' 를 알아보자
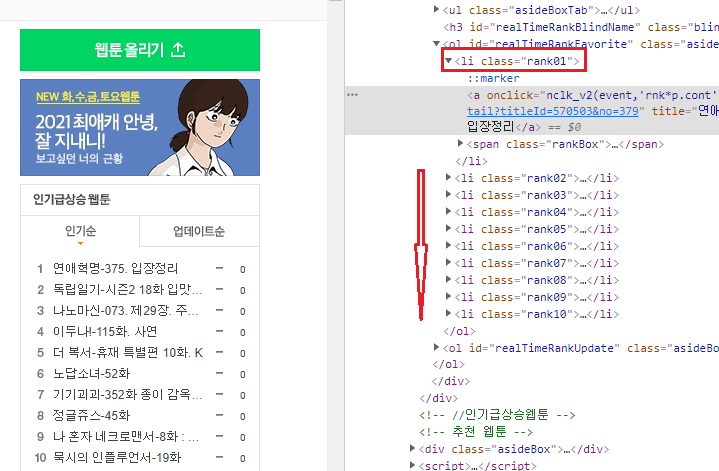
예를 들어 이 웹 페이지에서 '웹툰 올리기' 라는 버튼에 대해서 스크래핑을 하고싶다고 가정하자.
그러면 F12를 누른 후 아래 사진에 나와있는 버튼을 클릭 후 원하는 곳을 클릭하면 아래처럼 나온다 검사버튼을 가져다보면 이 버튼이 가지고 있는 특성을 볼 수 있는데 class를 특성으로 가져오면 쉬울 것 같다!
import requests
from bs4 import BeautifulSoup
url ="https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
*웹페이지에 특정 기능이 하나라면 "a" 위치는 생략 가능 하다
print(soup.find("a", attrs={"class":"Nbtn_upload"}))
find_next_sibling() 함수도 previous를 붙여서 이전것들을 들고 올 수 있다.
여러 형제들이 있으면 find_next_siblings()로 한번에 여러개를 들고 올 수 있다.
webtoon = soup.find("a", text="연애혁명-375. 입장정리")
print(webtoon)
이런 식으로 텍스트만 이용해서도 추출이 가능 하다.
03 BeautifulSoup4 활용 1
요일별 전체 들고 오기
import requests
from bs4 import BeautifulSoup
url ="https://comic.naver.com/webtoon/weekday"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
#네이버 웹툰 요일별 전체 목록 가져오기
cartoons = soup.find_all("a", attrs={"class":"title"})
for cartoon in cartoons:
print(cartoon.get_text())
...
보통아이
호수의 인어
다시 또 봄
가짜인간
호시탐탐
거래하실래요?
푸른불꽃
짝사랑의 유서
독신마법사 기숙아파트
샤인 스타
...
현재 페이지에는 없는 만화 정보를 들고 와 보기
검색을 해야 나오는 만화이다. 이 URL을 들고 파싱 해보자
똑같이 어떠한 목록을 들고 올지 검사를 눌러서 찾자! 현재 이 페이지에서 제목을 들고 오려고 하니 테이블로 구성이 되어있지만 <a>태그에는 딱히 다른 정보가 없다. 그래서 바로 위 부모의 <td>태그로 들고 와보자 안 될 수도 있다.
import requests
from bs4 import BeautifulSoup
url ="https://comic.naver.com/webtoon/list?titleId=675554"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
cartoons = soup.find_all("td", attrs={"class":"title"})
# print(cartoons)
title = cartoons[0].a.get_text()
print(title)
후기 + 10년 후 가우스
→ 다행히 잘 들고 온다! *.find_all() 함수는 리스트 형식으로 들고 온다는것을 명심 하자!
이제 이것을 활용해서 모든 제목 + 링크를 들고와서 링크를 클릭하면 페이지로 이동하도록 해보자!
import requests
from bs4 import BeautifulSoup
url ="https://comic.naver.com/webtoon/list?titleId=675554"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
cartoons = soup.find_all("td", attrs={"class":"title"})
for cartoon in cartoons:
title = cartoon.a.get_text()
link = "https://comic.naver.com" + cartoon.a["href"]
print(title, link)
잘 들고 온다! 링크는 컨트롤 + 마우스 왼클릭으로 하면 페이지로 이동 한다!
가우스 전자 평점 들고 오기
→항상 스크래핑시에는 검사를 통해 화면을 분석 해야 한다! 평점이 어떻게 구성되어있는지 한번 보자
평점을 들고 와야 하니 div안에 9.98이 어느 태그에 속해 있는지를 잘 봐야 한다.
# 평점 구하기
total_ratings = 0
cartoons = soup.find_all("div", attrs={"class":"rating_type"})
for cartoon in cartoons:
rating = cartoon.strong.get_text()
print(rating)
total_ratings += float(rating)
print("Total Ratings: ",total_ratings)
print("Average Ratings: ",total_ratings / len(cartoons))
9.98
9.98
9.97
9.97
9.97
9.98
9.97
9.97
9.97
9.97
Total Ratings: 99.72999999999999
Average Ratings: 9.972999999999999